
ChatGPT实践——如何用LangChain基于LLM构建一个应用程序
LangChain是什么
随着大语言模型的出现和发展,开发者们都会思考一个问题,如何利用这些新技术来搭建一个有用的应用程序。但若只是基于各个独立的技术,是很难满足我们对应用程序的需求的。而LangChain这样的工具就是用来解决这一问题的,它能够将多个不同的技术组合起来供开发者使用,从而让开发者得以便捷的实现一个有用的应用程序。
LangChain可以实现的应用场景
Agents
这里的Agents指的是一个系统,该系统可以使用大语言模型来与其他工具进行交互,从而实现如智能问答、智能操作或是其它连接硬件进行行动的功能。我能想到的是可以实现一个类似于Siri这样的手机软件助手,应该会比它智能一些吧,还有像是科幻片种的智能机器人。
Chatbots(聊天机器人)
这个其实就是基于LLM来做一个能够对话的机器人,像OpenAI的ChatGPT就能直接进行对话的。但它这里可以提供更多复杂的功能,让LLM能够更加定制化,适用更多的应用场景。
Generate Examples(生成例子)
可以基于我们之前的样例按照某个模板生成更多相似的样例。
Data Augmented Generation(增强的数据生成)
目前的LLM只能是基于已训练好的通用模型进行数据生成(或者叫做对话),但我们有很多场景都是特殊的,我们希望LLM能够对我们自己的私人文档进行总结或是基于私人文档进行问答对话,又或者希望我们和LLM的对话能够基于我们的某个数据库。而使用该工具就可以实现这些场景了。
Question Answering(问答)
可以创建基于某个或多个文档的问答系统。对于基于多个文档的问答系统,可以做到创建各个文档的索引,从而在问答时能够快速挑选出最相关的文档发送给LLM,而不用每次都把所有文档都发送过去。
这个我能想到的是,可以把公司的iwiki系统接入进去(当然,这只是假设,因为数据敏感要求,肯定不能这么做),这样我们就可以不仅限于倒排索引进行检索了。
Summarization(摘要)
将多个长文档总结凝练成一小段核心的摘要。
Querying Tabular Data(查询表格数据)
有许多数据都是表格型数据,比如CSV、EXCEL表格,比如SQL表格。LangChain可以用于处理这些表格数据。
Extraction(提取)
在我们工作场景中,大多数的API以及数据库处理的都是结构化的数据,因此,从一段文本中提取出我们所需要的结构化数据就显得很重要了。包括从一段文本中提取出一条或多条结构化数据插入到数据库中,以及从用户的查询中提取出正确的API参数等。
Model Comparison(模型比较)
在我们构建自己的应用程序时,肯定会涉及到对不同的模型、参数等进行选择。LangChain提供了一个叫做ModelLaboratory的工具,可以让开发者便捷的检验出不同的模型、参数等带来的不同效果,以此来快速判断出该如何进行选择。
LangChain的生态系统
LangChain集成了很多LLM以及各种常用的工具包,比如OpenAI、Wolfram Alpha Wrapper等。
| AI研究 | 数据管理 | 自然语言处理 | 搜索引擎 | 其他 |
|---|---|---|---|---|
| AI21 Labs | AtlasDB | Banana | Google搜索封装器 | Chroma |
| CerebriumAI | DeepInfra | Hugging Face | Google Serper封装器 | Cohere |
| Deep Lake | Graphsignal | NLPCloud | OpenSearch | DeepInfra |
| ForefrontAI | Milvus | Petals | SearxNG搜索API | GooseAI |
| OpenAI | Pinecone | PromptLayer | SerpAPI | Hazy Research |
| StochasticAI | PGVector | Weaviate | Wolfram Alpha封装器 | Modal |
| Qdrant | Runhouse | |||
| Unstructured | Weights & Biases |
详见:https://langchain.readthedocs.io/en/latest/ecosystem.html
使用LangChain做了几个应用程序demo
结合自己的notion文档做对话
demo背景
因为我有每天做工作记录的习惯,所以想尝试使用这个工具结合自己的notion文档,看能否使用它对自己的notion文档做问答对话。
我的工作记录的notion文档部分截图如下:

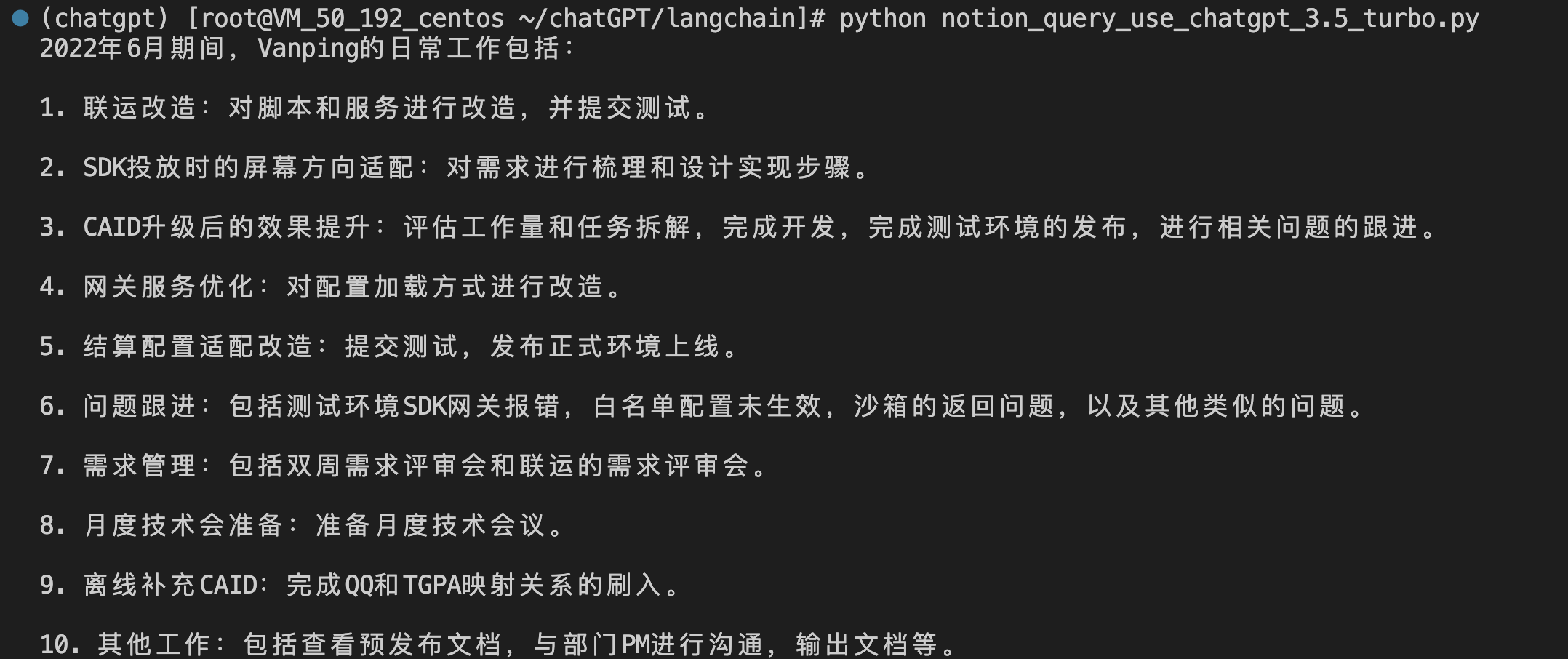
问题一:把vanping在2022年6月的工作做一下总结
执行脚本运行的结果:
问题二:在2022月6月,什么工作是vanping的重点

代码
import os
from langchain.chains.question_answering import load_qa_chain
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import UnstructuredFileLoader
openaichat = ChatOpenAI(model_name="gpt-3.5-turbo")
loader = UnstructuredFileLoader("./vanping_work.txt")
docs = loader.load()
chain = load_qa_chain(openaichat, chain_type="stuff")
query = "在2022月6月,什么工作是vanping的重点"
result = chain.run(input_documents=docs, question=query)
print(result)
小结
这里用到了LangChain的Models、Indexes模块。
看起来使用该工具是能够非常便捷的导入文档以及和chatGPT做对话交互的。但我这里也只是展现了一个简单的demo,若是多加利用,应该是很好用的。
让应用程序扮演某个角色和我对话
demo背景
我想尝试使用LangChain中的chains,看看能否用加前后缀的方式,让应用程序可以扮演某个角色和我进行对话。
角色零:通用模型。问题:你每天都在干吗?
运行结果:

角色一:阴阳怪气的人。问题:你每天都在干吗?
运行结果:

角色零:通用模型。问题:给我讲下ChatGPT的应用场景?
运行结果:
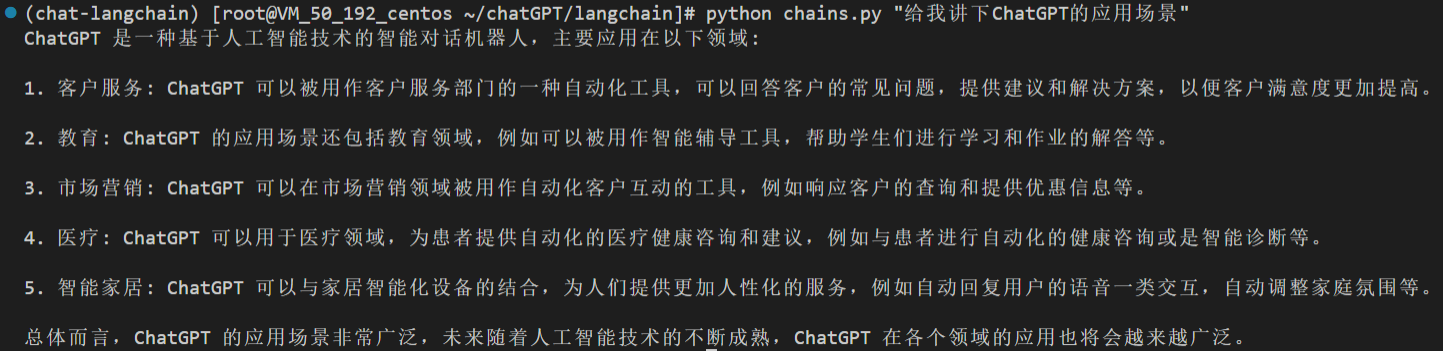
角色二:言简意赅的人。问题:给我讲下ChatGPT的应用场景?
运行结果:

代码
import os
import sys
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.chains import LLMChain
os.environ["OPENAI_API_KEY"] = "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"
openaichat = ChatOpenAI(model_name="gpt-3.5-turbo")
prompt = PromptTemplate(
input_variables=["query"],
template="假设你是个言简意赅,每次说话都不超过30个字的人,{query}",
)
chain = LLMChain(llm=openaichat, prompt=prompt)
result = chain.run(sys.argv[1])
print(result)
小结
这里用到了LangChain的Models、Prompts、Chains模块。
这应该是Chains最简单的用法了。实际上Chains是有很多高级的用法。可以参考:https://langchain.readthedocs.io/en/latest/modules/chains.html
私人问答助手(与搜索引擎结合,且具备记忆能力)
demo背景
当前的很多LLM模型都是基于历史的数据训练得来的,比如ChatGPT,就仅能支持查询21年以前的事件,之后的事件它就无能为力了。

比如,当我想知道”当前NBA赛季,洛杉矶湖人队的常规赛平均得分是多少? 与上赛季常规赛平均水平相比百分比变化如何?”
它的答复是这样的:

从结果我们就能看到,它对于这种事情是一窍不通的。
而如果我们想做一个私人问答助手,肯定是不能不知道当前时事的,因此,我就使用LangChain结合搜索引擎来做一个助手。
私人问答助手的答复
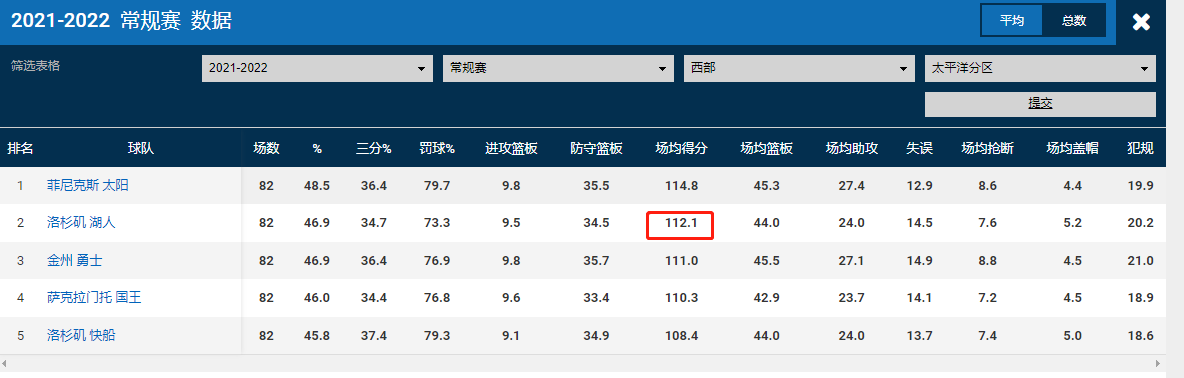
问题一:当前 NBA 赛季洛杉矶湖人队的常规赛平均得分是多少? 与上赛季常规赛平均水平相比百分比变化如何?
问题二:该队当前的主力队员有谁?
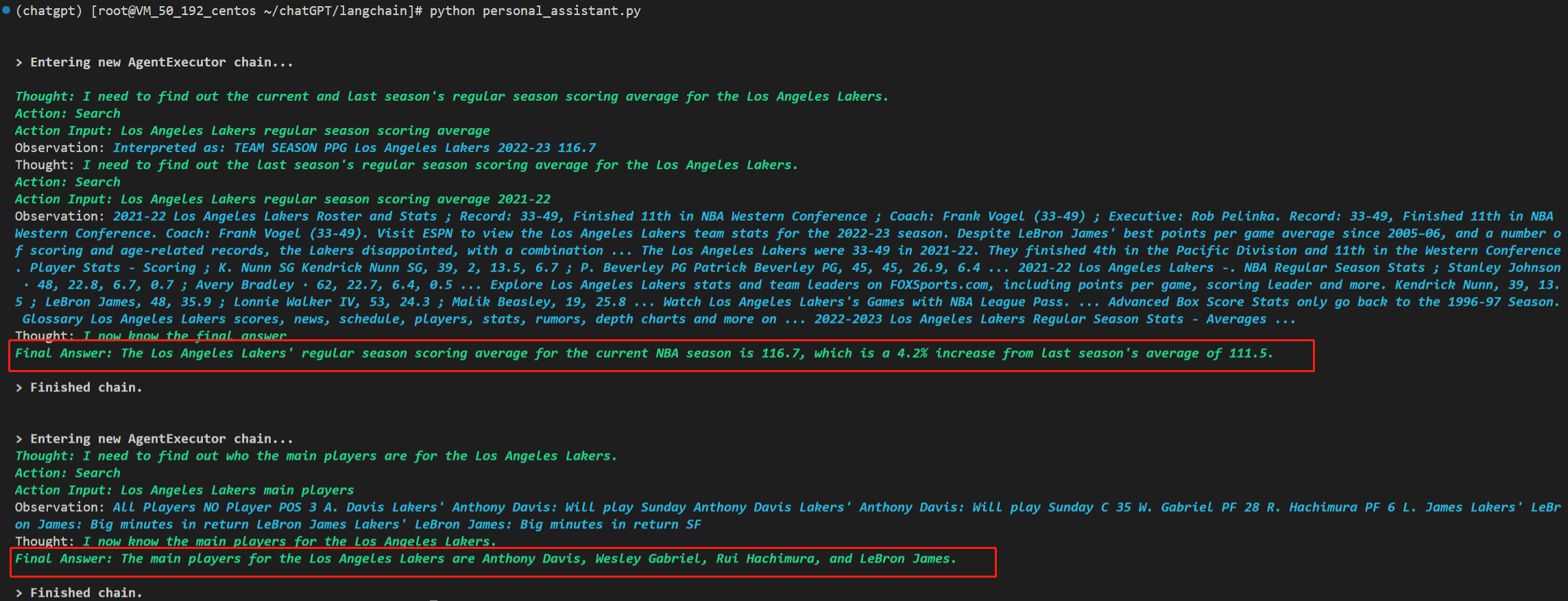
针对以上两个问题,这个私人问答助手都有答复。
答复一:洛杉矶湖人队本赛季常规赛场均得分为 116.7,比上赛季的场均得分 111.5 提高了 4.2%。
答复二:洛杉矶湖人队的主力球员是Anthony Davis,Wesley Gabriel,Rui Hachimura,LeBron James。
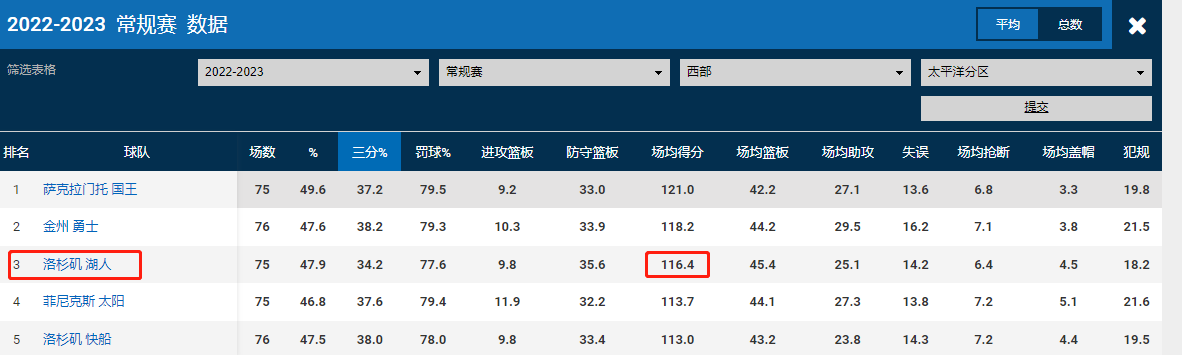
我在NBA APP中查了下球队数据,看起来也不十分精确,但相差也并不大。
我在这个demo中用到了LangChain的Memory、Agents模块,以及GoogleSerperAPIWrapper工具。
我还试验了一下,如果不要Memory模块,那么输出的结果会是如下这个样子。
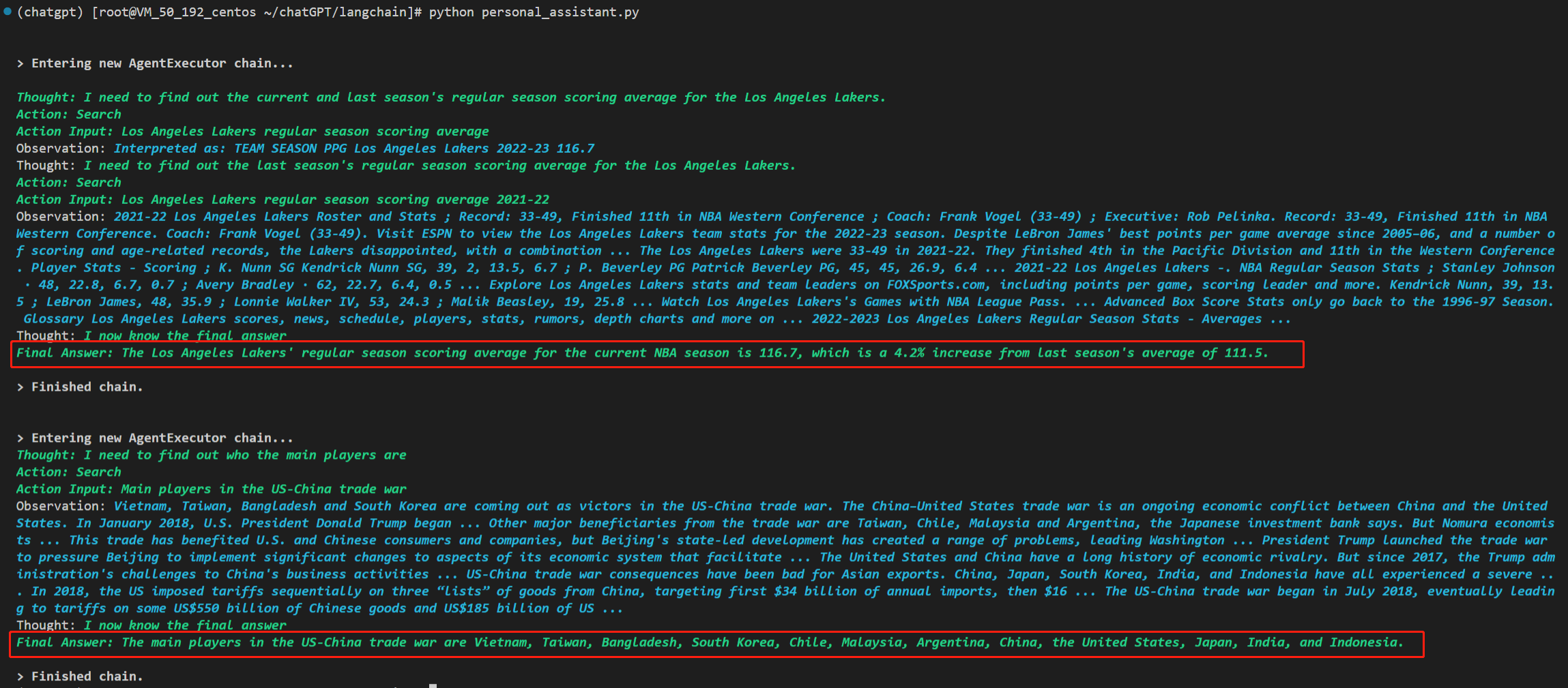
第一个答复还依旧正常,但第二个答复就是胡说八道了:美中贸易战的主要参与者是越南、台湾、孟加拉国、韩国、智利、马来西亚、阿根廷、中国、美国、日本、印度和印度尼西亚。
代码
from langchain.agents import ZeroShotAgent, Tool, AgentExecutor
from langchain.memory import ConversationBufferMemory
from langchain import OpenAI, LLMChain
from langchain.utilities import GoogleSerperAPIWrapper
search = GoogleSerperAPIWrapper()
tools = [
Tool(
name = "Search",
func=search.run,
description="useful for when you need to answer questions about current events"
)
]
prefix = """Have a conversation with a human, answering the following questions as best you can. You have access to the following tools:"""
suffix = """Begin!"
{chat_history}
Question: {input}
{agent_scratchpad}"""
prompt = ZeroShotAgent.create_prompt(
tools,
prefix=prefix,
suffix=suffix,
input_variables=["input", "chat_history", "agent_scratchpad"]
)
memory = ConversationBufferMemory(memory_key="chat_history")
llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=prompt)
agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools, verbose=True)
agent_chain = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True, memory=memory)
agent_chain.run(input="What is the regular season scoring average for the Los Angeles Lakers in the current NBA season? How is the percentage change compared to last season's regular season average?")
agent_chain.run(input="Who are its main players?")
小结
这里用到了LangChain的Models、Memory、Chains、Agents模块。
制作一个小助手算是非常常见的功能,我这里也只是简单的试用了一下。如果有更复杂的需求,可以参考文档:https://python.langchain.com/en/latest/use_cases/personal_assistants.html
总结
本文对LangChain做了一些简单的介绍,重点是后面列举了三个应用程序Demo。每个应用程序Demo虽然都比较简单,但也算是试用了一下LangChain所提供的一些功能。参考LangChain的官方文档,理论上就能实现很多场景更复杂的AI应用。
参考资料
LangChain官方文档:https://python.langchain.com/en/latest/index.html
ChatGPT分享-如何开发一个LLM应用:https://www.51cto.com/article/749570.html
学会任务理解、真正运算和时事搜索,GPT:我将以高达形态出击:https://km.woa.com/articles/show/573744
LangChain:Model as a Service 粘合剂,被 ChatGPT 插件干掉了吗?:https://foresightnews.pro/article/detail/28959