背景
如果我们需要在生产环境中修改MySQL数据库中某个库表的结构。那么,需要考虑哪些要点,才能确保不会出问题呢?
碰到的问题
这里先描述一下我在生产环境MySQL数据库中修改库表结构时遇到的问题。
在开发过程中,我发现MySQL中某个库表需要添加一个字段,比如库表:
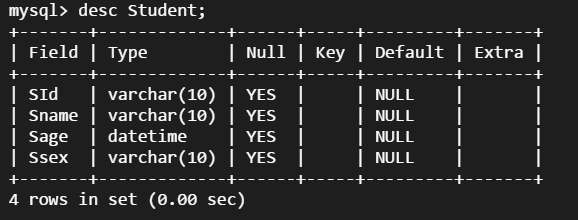
需要给Sname后面添加一个字段:Sheight。那么就使用命令:alter table practice.Student add column Sheight int(4) not null default 0 comment '"身高"
输入完这个命令后,我就去做别的事情去了。
直到过了一小会,有人反馈说线上的系统有些界面没有数据。这个时候我才意识到,是这个操作出了问题。导致了线上bug。
问题的解决
我立马查看这个操作,发现还没有执行结束。首先kill了这个执行任务,于是线上系统恢复了正常。
导致该问题的原因
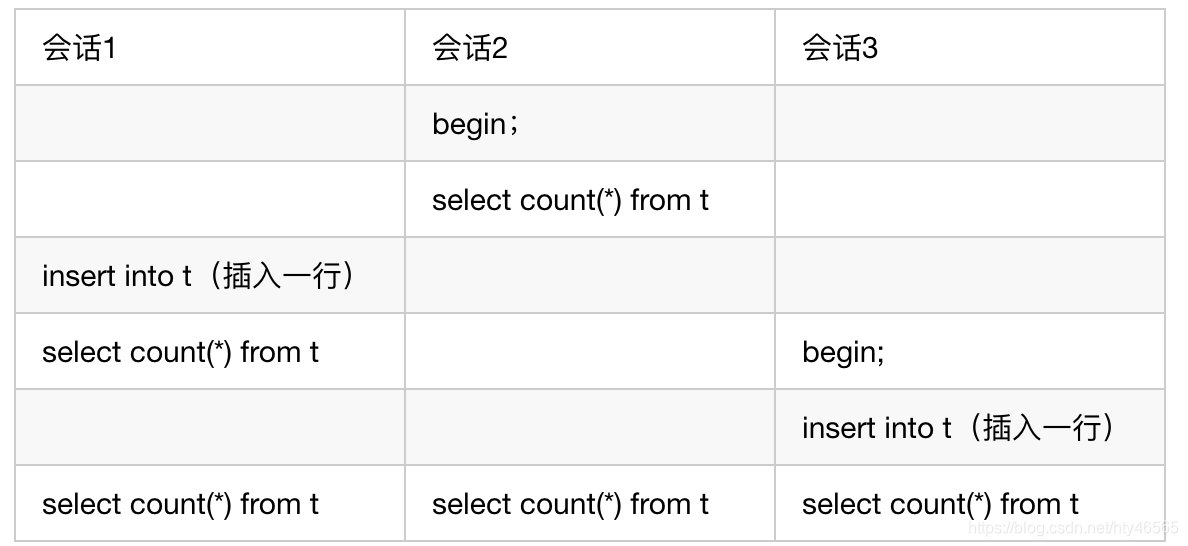
当时,我用命令:show processlist查询,看到这个语句的State显示的是:Waiting for table metadata lock。我们知道,这个状态是说,该表在等待获取表的metadata lock,也就是MDL。
也就是说,由于前面有MDL读锁没有被释放,因此我这个命令也就获取不到MDL写锁。导致后面再过来的各种操作都无法被执行,都在等待MDL读锁。
这里解释下metadata的概念,metadata lock(MDL)也就是元数据锁,它是一种表级锁。
各种对该表的操作,比如增删改查,都会占有MDL的读锁。当修改表结构时,会占用MDL的写锁。
读锁和读锁之间互不冲突,而读锁与写锁、写锁与写锁之间互相冲突。
简单说,就是对一个表增删改查同时进行,MDL锁不会冲突,我们可以用多线程同时执行这些操作,只会导致行锁,而不会锁整个表。
但是,如果在对表增删改查的同时,要对表结构进行修改,那么就会造成锁等待的状态。
如果有一个长事务在对该表进行操作,那么在修改表结构时,就会有状态:Waiting for table metadata lock,也就是锁等待。如果这个时候,另外又有查询操作过来,那么,后面这个操作就也要进行Waiting for table metadata lock,也就是锁等待了。当然,对该表的查询操作就会全部阻塞。
我当时的情况就是这样,有一个事务操作了该表,但是可能由于大意没有关掉该事务,该事务长时间存在。而我同时又进行表结构的更改,于是导致了这次事故。
如何做
首先,我们要了解一下有没有什么事务对该表进行了操作,却长期没有提交。因为,只有对该表操作的事务最终提交了,MDL锁才会被释放。
换句话说,如果某个事务对该表进行了操作,比如读操作,但是最终没有做提交,那么,该事务依然会占用MDL锁的。
查看事务可以用命令:SELECT * FROM information_schema.INNODB_TRX。
做完这一步之后,基本上可以避免出现Waiting for table metadata lock的情况了,但还有一点需要注意,就是线上会不会对该表进行频繁的操作,
有些热表可能一直处于有人在查询的状态,这种时候怎么做呢?
我们可以在变更表结构的命令中添加一个超时时间,如果这个命令在该时间段内一直无法执行,那么会自动超时的,起码可以保证不会长时间的影响用户的操作。
该命令为:alter table practice.Student wait 100 add column Sheight int(4) not null default 0 comment "身高"
总结
在生产环境中变更MySQL数据库中库表结构是一件比较有风险的事情,所以一定要三思而后行,避免引起任何可能的线上事故。