背景
之前写过关于内存管理源码分析的博客。大体介绍了什么是页、区、slab缓存,以及内核获取、释放页的接口,分配、释放slab缓存的接口。进程地址空间简单的说就是用户空间中进程的内存,我们叫这内存为进程地址空间。本篇博客借助linux源码大体分析进程地址空间的相关知识。
进程控制块
既然我们要聊一聊进程地址空间,那么不可避免的就要先聊一下进程控制块,进程控制块的概念想必大家不会陌生。一个进程是由一个进程控制块来描述的。所以,可想而知,进程控制块中一定包含有进程地址空间的描述结构体。这个描述进程地址空间的结构体就是mm_struct。先来看下task_struct结构体。(位于linux/sched.h中)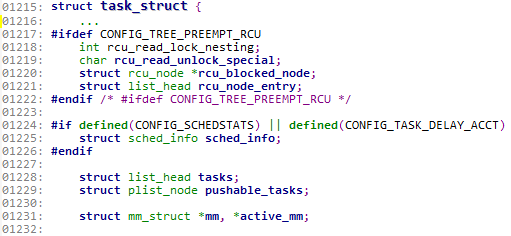
这是截取了task_struct中的一部分代码。
mm_struct
接下来我们就重点的看一下mm_struct结构体。此结构体是用于描述进程地址空间的,所以每个进程都有唯一的mm_struct结构体,即唯一的进程地址空间。我们来看一下此结构体的部分源码(位于linux/mm_types.h中)。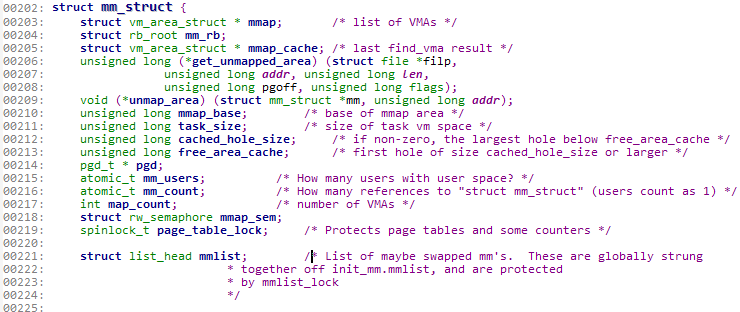
203行的mmap域与204行的mm_rb域描述的对象是相同的。为什么要用不同的方式来组织相同的对象呢?原因在于,用mmap作为链表可以方便遍历所有元素;而mm_rb作为红黑树,适合于搜索指定的元素。
215行的mm_users域与216行的mm_count域都是原子数,用于用户引用此进程地址空间(也就是此结构体)的计数。区别在于,mm_users表示的是有多少进程在引用此进程地址空间,若其为3,则表示有3个线程共享此进程地址空间。mm_count表示的是如果有用户使用此进程地址空间,那么此域值为1,否则域为0。当mm_count为0时,此结构体就会被撤销。
所有的mm_struct结构体都通过双向链表mmlist域连接在一起。双向链表的链表头是init进程的进程地址空间。
mm_struct结构体的源码就分析这么多。
我们都知道一个进程有唯一的一个mm_struct结构体,即一个进程有唯一的一个进程地址空间。那么,在创建一个新进程时,mm_struct是如何被创建的?
我之前有一篇博客讲过slab缓存的作用以及用法,提到过slab缓存的作用在于快速为常用的结构体分配空间。很显然mm_struct是一个常用的结构体,新进程的mm_struct结构体是通过allocate_mm()宏(位于linux/fork.h中)从mm_cachep slab缓存中分配得来的。前面提到过,一个进程有唯一的进程地址空间,而线程没有自己的进程地址空间,不同线程共享同一个进程地址空间。是否共享地址空间几乎是进程和Linux中线程间本质上的唯一区别。那么,内核线程与进程地址空间的关系是如何的呢?
内核线程与进程地址空间
内核线程没有进程地址空间,当然也就没有mm_struct结构体。所以内核线程对应的进程描述符中的mm域为NULL。请大家回想一下在一个进程被调度时进程地址空间是如何进行转换的?
实际上是该进程的mm域指向的进程地址空间被装载到内存中,进程描述符中的active_mm域被更新指向新的进程地址空间。
而内核线程是没有进程地址空间的,所以其mm域为NULL,当内核线程被调度时,内核发现它的mm域为NULL,就会保留前一个进程的进程地址空间,更新内核线程进程描述符中的active_mm域指向前一个进程的进程地址空间。因为内核线程不访问用户空间的内存,所以它们仅仅使用地址空间中和内核内存相关的信息,这些信息的含义和普通进程完全相同。
上面讲过的mm_struct结构体是描述进程地址空间的,而通过分析源码我们发现,mm_struct结构体并没有涉及到具体的虚拟内存区域,如内存区间何起何止。但在mm_struct结构体的第一个域mmap指向的vm_area_struct结构体中描述了虚拟内存区域。我们来看看这个结构体。
vm_area_struct
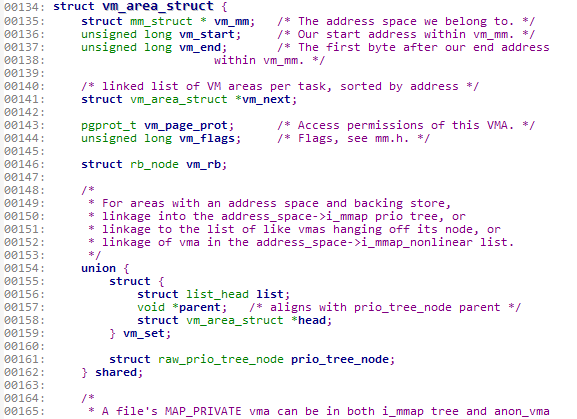
这里截取了部分vm_area_struct的源码。(位于linux/mm_types.h中)
其中136行的vm_start域是进程地址空间的起始地址,137行的vm_end域是结束地址。
135行的vm_mm域指向相关的mm_struct结构体。也就是此虚拟内存区域相关的进程地址空间。
聊完虚拟内存区域VMA,接下来就可以聊一下如何为一个进程地址空间创建一个VMA。
do_mmap
内核使用do_mmap函数创建一个新的线性地址空间,由于新创建的地址空间若是与原有的地址空间相邻内核会自动进行合并,所以更严格的来说,do_mmap不一定总是创建新的VMA,而可能是扩展已有的VMA。来看看do_mmap的源码(位于linux/mm.h中)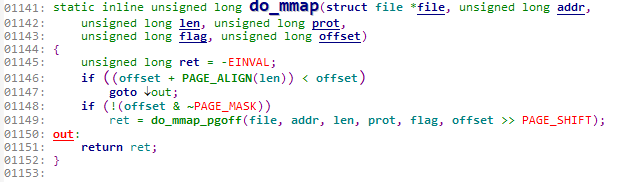
函数参数中的file、offset、len域分别指要映射的文件、要映射的起始偏移地址、映射的长度。
其中file域可以为空,这时指此次映射与文件无关,这叫做匿名映射,如果是与文件有关的,叫做文件映射。
addr是可选参数,它指定搜索空闲区域的起始位置。prot参数指定内存区域中页面的访问权限。flag参数指定了VMA标志。
有do_mmap来创建新的地址空间,当然就有do_munmap来删除地址空间。该函数定义在mm/mmap.c中。这里就不赘述了。
总结
本篇博客先介绍了什么是进程地址空间,然后介绍了其描述符mm_struct,一个进程对应一个进程地址空间,也就是说task_struct对应一个mm_struct。内存描述符mm_struct介绍完后聊了一下其与内核线程的关系,因为我们知道,内核线程是没有进程地址空间的。所以内核线程使用前一个进程的mm_struct。接下来介绍了一下vm_area_struct结构体,它描述了虚拟内存区域,也就是进程地址空间中的内存区域。最后简要说了一下创建线性地址空间的函数do_mmap。