背景
我们使用Go语言开发了一个后台服务,在发布测试环境后,发现内存使用量会随着时间的推移持续增加。因此服务的Pod会隔一段时间重启一次,因此,需要排查一下该问题。此文是对排查过程的记录以及排查后的思考总结。
环境准备
本文假设开发机环境中已经安装了go、pprof、graphviz,并且后台服务中已经集成了pprof。
业务中内存泄漏的现象以及排查思路
内存泄漏的现象
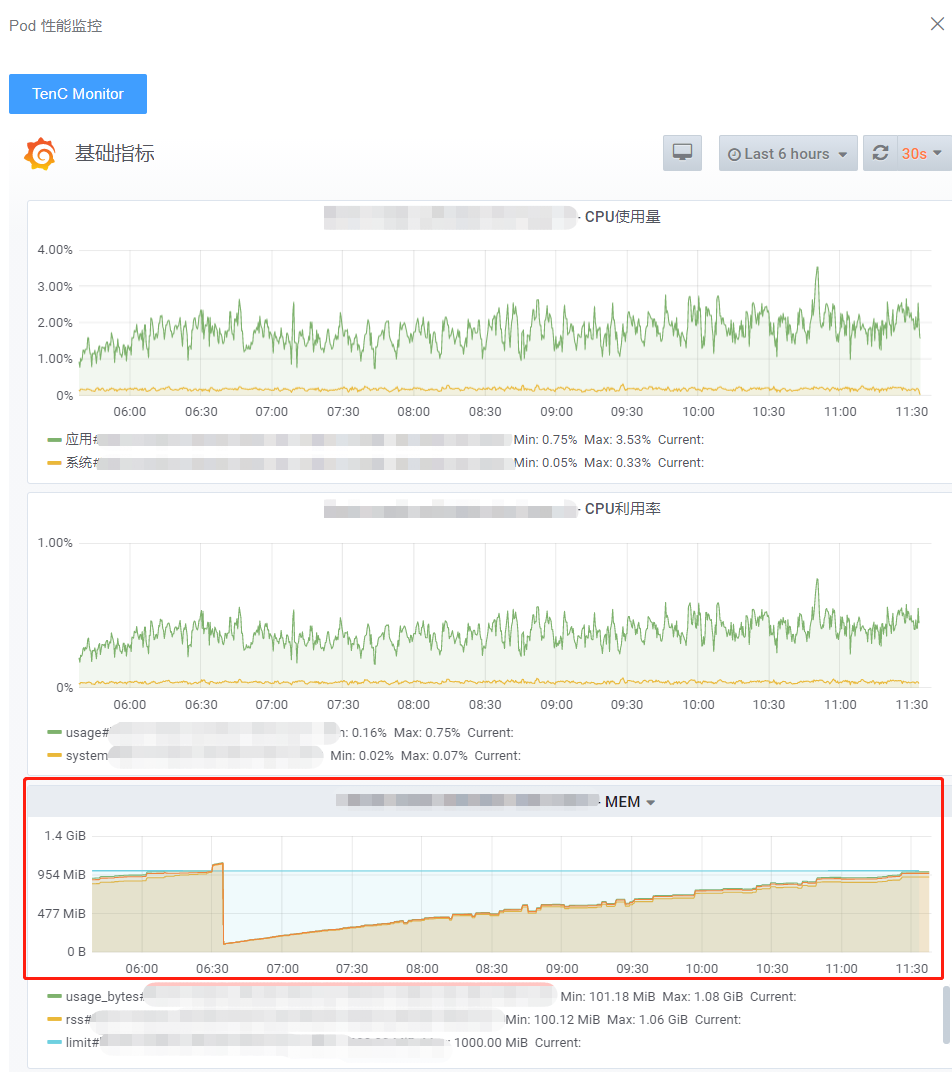
我们将服务发布到测试环境中之后,可以从内存监控的看板中看到,内存使用量随着时间的推移会一直增加,而且会一直达到内存设置的限制并且重启Pod。这种情况的出现,就是内存出现了泄漏的问题。
排查思路
使用Go语言开发的后台服务,在遇到这种情况时,我们首先应该想到的是可能Goroutine出现了泄漏,也就是说,可能开启了大量Goroutine,但是没有进行回收导致。因为Go语言程序的基本运行单位就是Goroutine,因此大多数内存泄漏都是Goroutine的泄漏。我们按照重点来排查,可以节约时间和精力。
我先在开发机上运行起来服务,然后请求pprof来查看Goroutine的运行情况:
请求http://10.111.55.111:8081/debug/pprof/,(10.111.55.111为我的开发机IP)可以看到: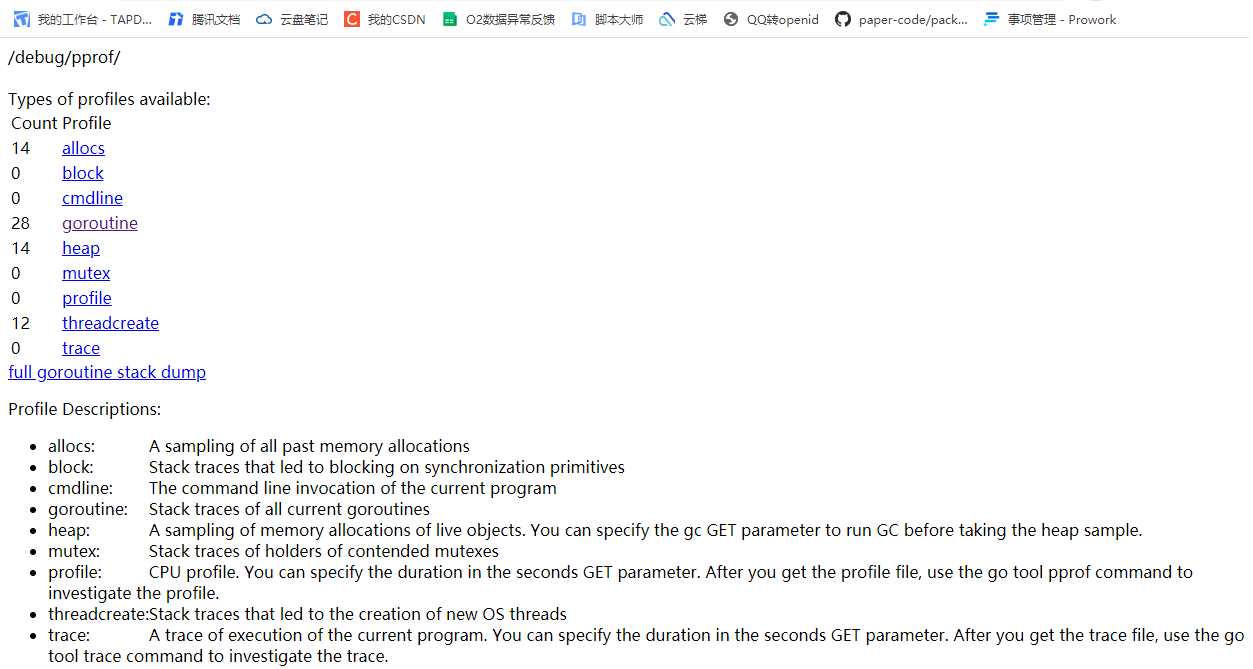
然后我们选择查看其中的Goroutine: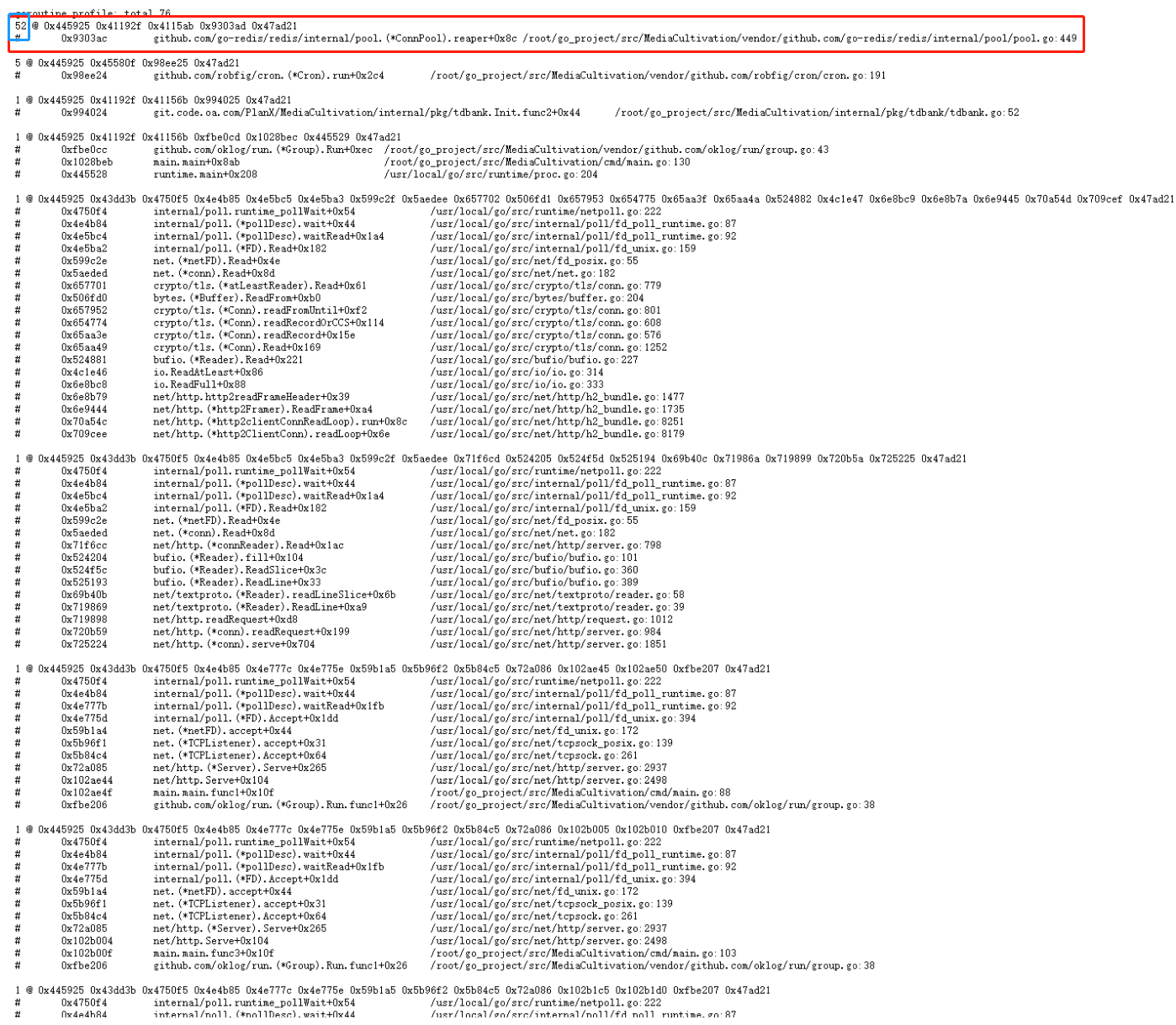
再过一段时间后,我们再次刷新一下,再次查看Goroutine的数量: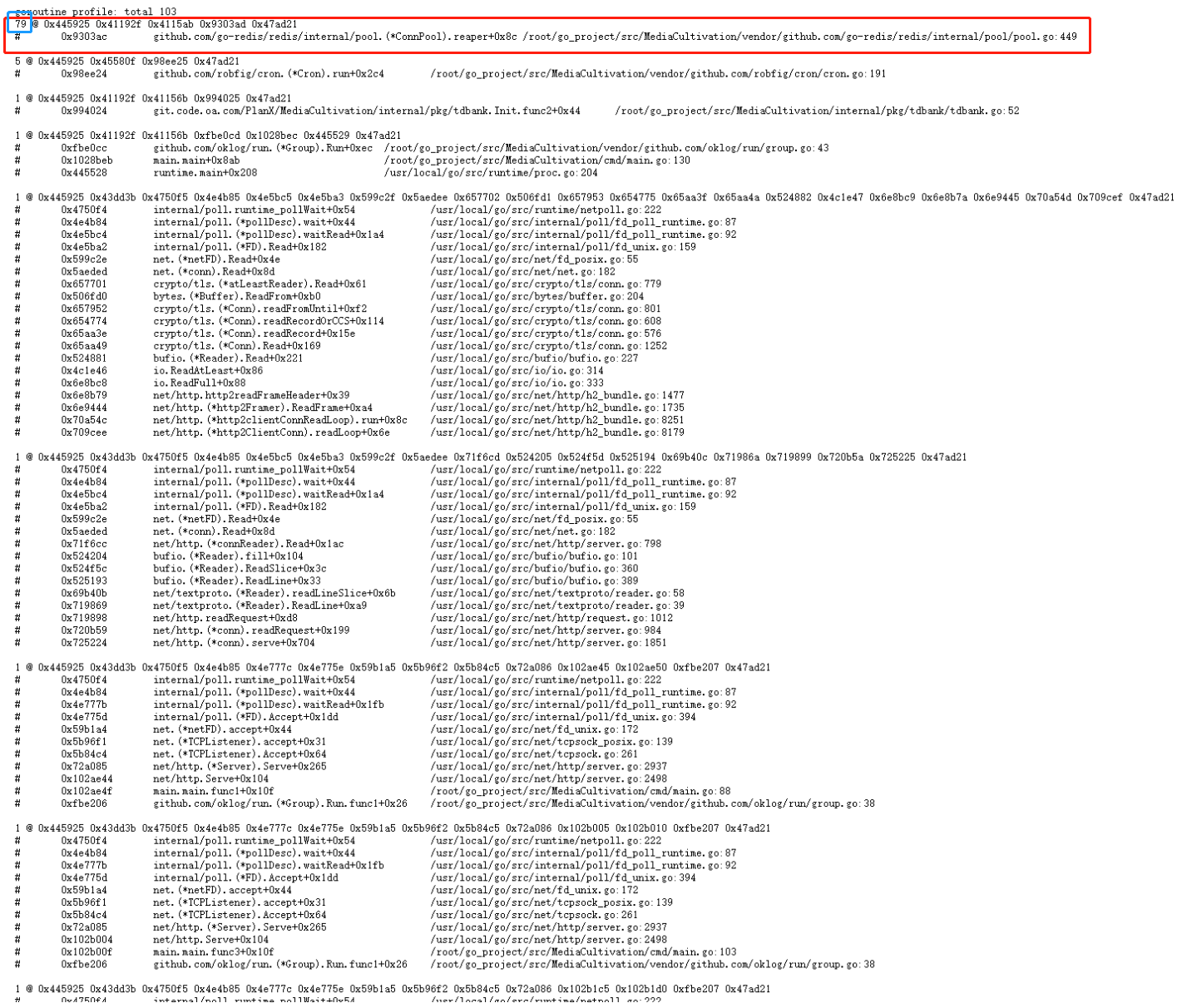
可以发现蓝框标记的Goroutine数量一直随着时间的推移而增加,这就是内存泄漏的Goroutine。如果发现变化比较缓慢,我们也可以进行压力测试后再观察。
按照展示的调用信息,我们定位到Redis线程池实现中的这行代码。可以看到,是这行代码发生阻塞,这行代码是做什么的呢?其实就是Redis线程池的定时回收空闲线程功能,只是我们有大量的空闲线程还没有到时间被回收。于是阻塞在了这里。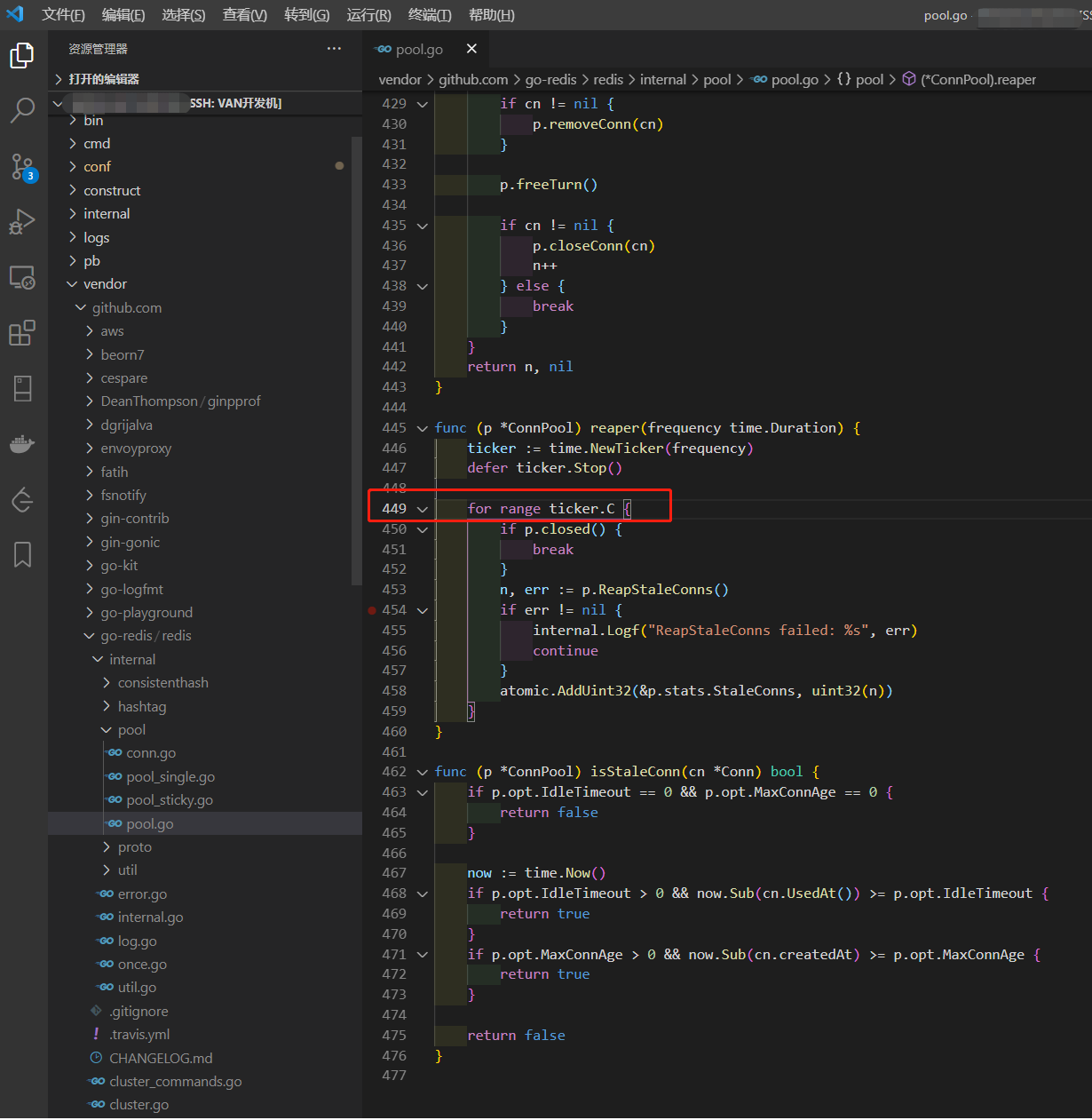
接着往上找调用函数,就可以发现是新建Redis连接池时调用的该函数。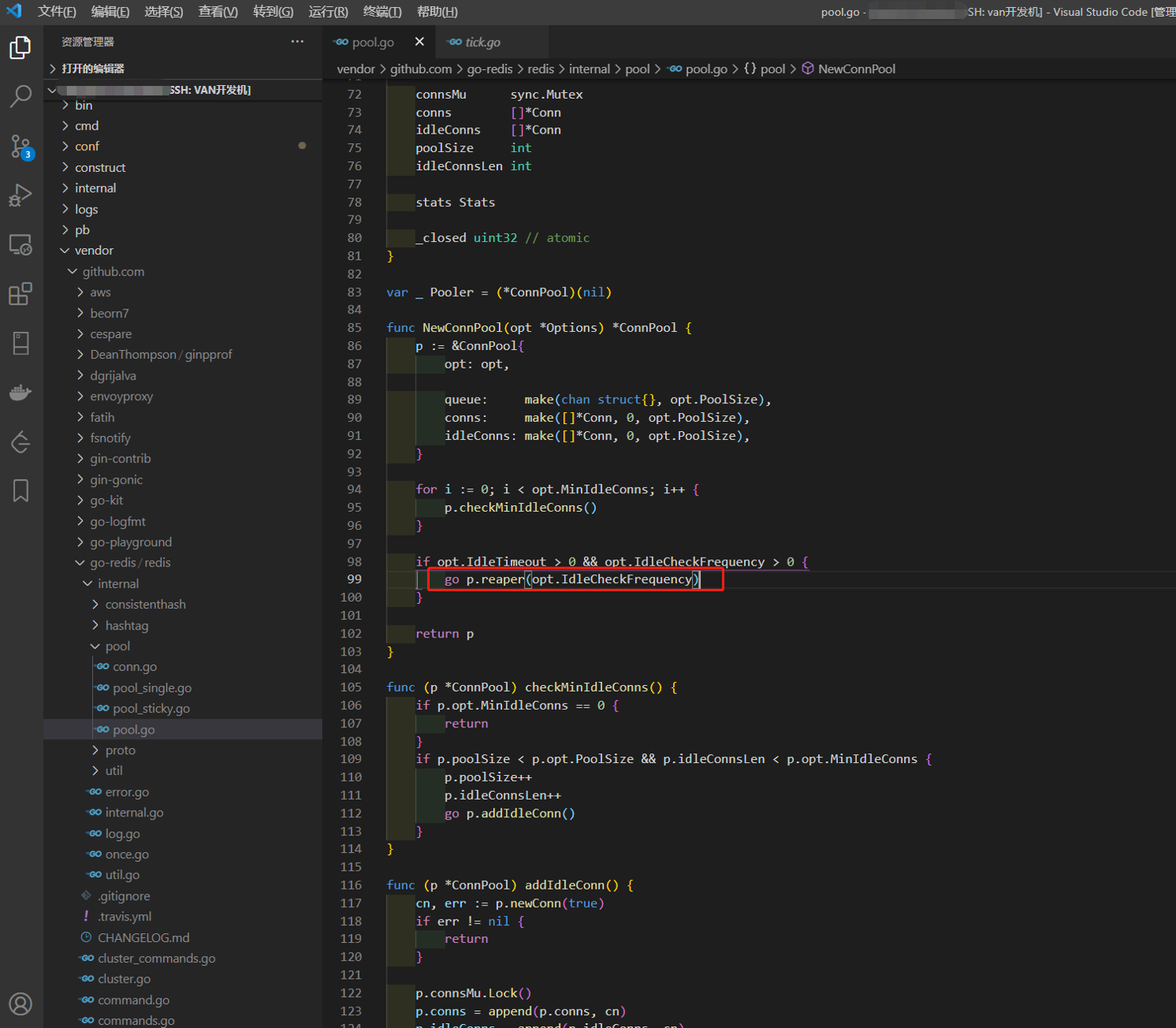
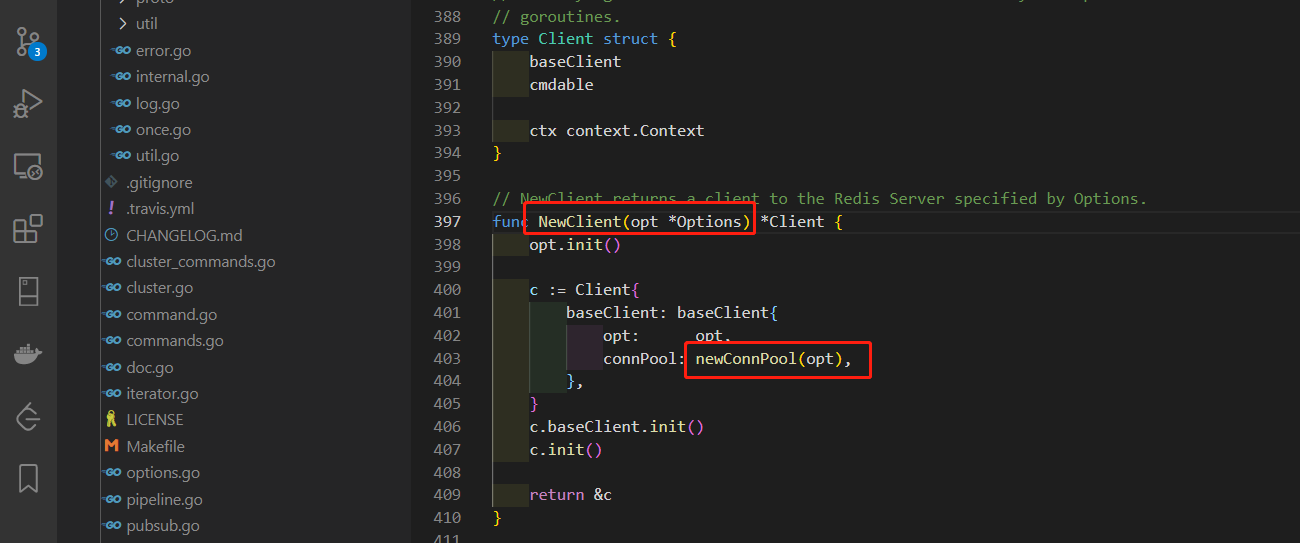
最终可以定位到导致内存泄漏的原因:其实就是我们在很多地方新建了Redis连接池,但是设置的关闭空闲连接的时间又不合理,导致在大量请求过来时,就会不断的累计连接数量,于是也就有大量的连接未关闭并一直阻塞在定时器那里。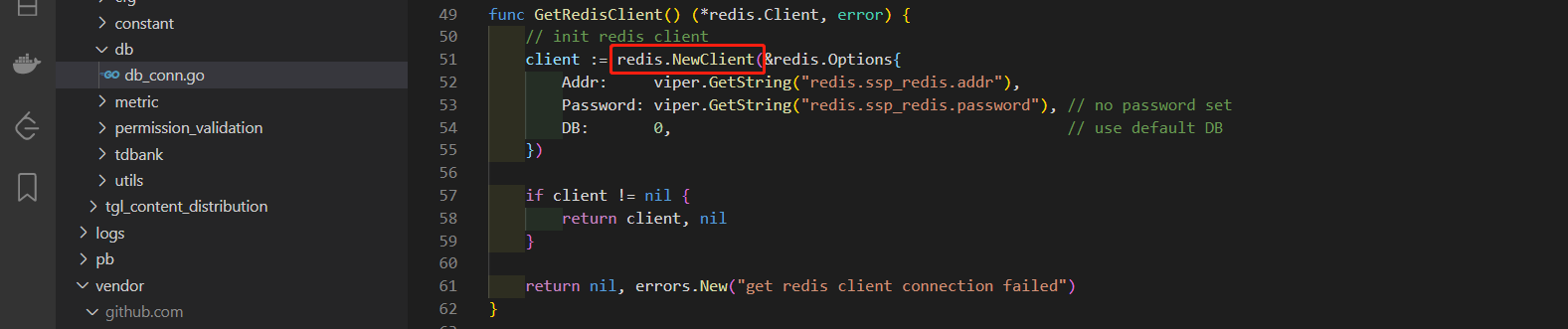
后续我们将Redis线程池做成了一个公共引用,只在初始化服务时初始化一些我们需要的连接量,于是该内存泄漏问题得到了解决。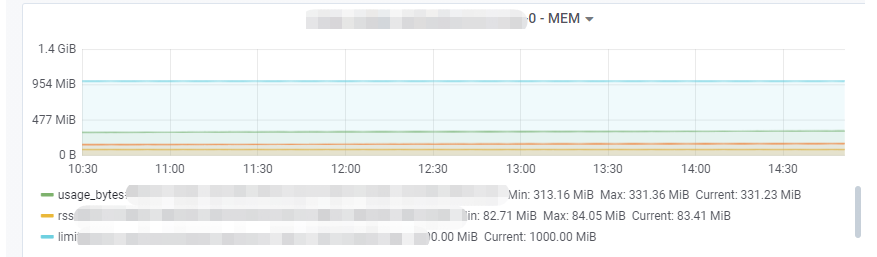
可以看到,内存使用量不再随着时间的推移而不断增加。而且Goroutine的数量也不再异常增加了。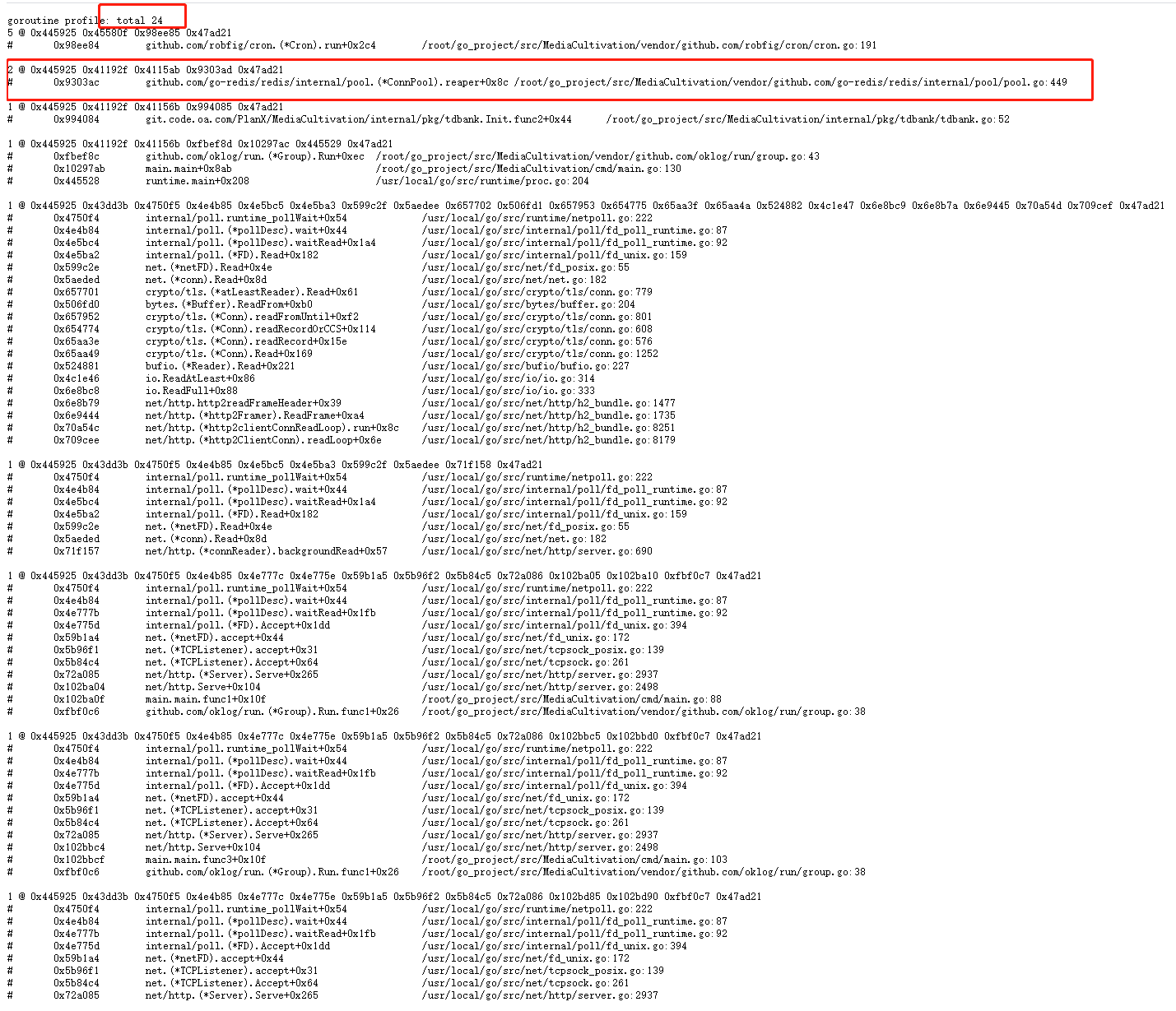
内存泄漏的拓展思考
Goroutine泄漏为什么会导致内存泄漏
排查了一个Goroutine泄漏导致的内存泄漏例子后,我们再思考一下,为什么Goroutine的泄漏会导致内存泄漏呢?
首先,我们需要清楚什么是Goroutine泄漏。
Goroutine泄漏是指,我们创建的Goroutine没有在我们预期的时刻关闭,导致Goroutine的数量在服务端一直累积增加,最终影响到服务的性能。
然后,为什么Goroutine的泄漏会导致内存泄漏呢?
有两点原因:
- Goroutine本身的堆栈大小是2KB,我们开启一个新的Goroutine,至少会占用2KB的内存大小。当长时间的累积,数量较大时,比如开启了100万个Goroutine,那么至少就会占用2GB的内存。
- Goroutine中的变量若指向了堆内存区,那么,当该Goroutine未被销毁,系统会认为该部分内存还不能被垃圾回收,那么就可能会占用大量的堆区内存空间。
Goroutine会发生泄漏的场景总结
1 从channel中读或写,但没有对应的写或读
我们都知道,channel分为两种类型,unbuffered channel和buffered channel,我们先讨论unbuffered channel。
在channel被创建后未被关闭前,我们若从channel中读取数据,但又一直没有数据写入channel中,那么channel就会进入等待状态,对应的Goroutine也就会一直阻塞着了。对应的,当我们往channel中写数据,但又一直没有从channel中读。那么也会出现被阻塞的情况。
以从channel中读,但没有写为例:
func ChannelLeak(w http.ResponseWriter, r *http.Request) {
ch := make(chan int)
go func() {
value := <-ch
fmt.Println("value is: ", value)
}()
}以上程序就会导致Goroutine的泄漏。
至于buffered channel,其实和unbuffered channel情况是类似的,只是buffered channel是读完缓存后,或写完缓存后会导致阻塞,这里就不再赘述了。
2 在使用select时,所有的case都阻塞
可以看一下这个例子:
func add(c, quit chan int) {
x, y := 0, 1
for {
select {
case c <- x:
x = x + y
case <-quit:
fmt.Println("quit")
return
}
}
}
func Add() {
c := make(chan int)
quit := make(chan int)
go add(c, quit)
for i := 0; i < 10; i++ {
fmt.Println(<-c)
}
// close(quit)
}我们可以看到,当Add函数for循环了10次之后,add函数就会一直阻塞了,也就出现了Goroutine泄漏。
正确的做法应该是在合适的时间将quit关闭,那么add协程就可以安全退出了。
3 Goroutine进入死循环
由于代码逻辑上的bug,Goroutine进入了死循环,则会导致资源一直无法释放。
如下例:
func loop() {
for {
fmt.Println("loop")
}
}
go loop()Goroutine泄漏的预防
以上总结了四个比较常见的Goroutine泄漏的场景,我在这次业务中碰到的内存泄漏问题就是由于开启了大量Goroutine,但定时器一直在等待channel数据的到来,导致长时间阻塞导致。就是以上介绍的常见场景的第一种情况。
至于Goroutine泄漏,应该是预防重于解决,预防Goroutine泄漏的方法如下:
- 在Goroutine中使用到了channel时,要考虑清楚channel何时可能会阻塞,以及阻塞时的具体情况
- 创建了一个Goroutine时,就要考虑清楚Goroutine应该如何结束
- 注意代码程序的逻辑,切忌在代码中出现死循环
总结
pprof不仅是一个可以用于做性能优化的工具,也是一个可以用来排查问题的好工具。善用这类工具对于Go开发者来说是非常重要的。另外,在写Go语言代码时,要重视Goroutine泄漏的问题,这种问题不出现则已,如果出现,就很可能会导致线上问题,后果是非常严重的。