背景
近期业务上有一个需求:需要将我们已有的一些视频素材作为数据源,结合有节奏感的BGM,输出一个能够卡点的视频素材。类似于这样的功能在很多视频剪辑软件如剪映、快影中都能够看到,它们会让用户上传多个视频,然后再让用户挑选一个喜欢的BGM,就可以快速输出一个卡点好的视频。我们利用librosa简单实现了这样的功能,并结合后台的一系列自动化工具,使用户能够快速得到大量的具有音乐卡点效果的视频素材,我们将该能力与现有系统相结合,提升了混剪视频制作效率并降低了制作成本。
本篇文章去除了业务上的一些细节,将如何利用开源工具快速实现音乐卡点功能做了总结整理。
使用到的开源工具
OpenCV:OpenCV(开源计算机视觉库)是一个开源计算机视觉和机器学习软件库。可以用于图像处理、视频处理、特征提取等很多场景。这里我们用它来获取视频帧率、尺寸、帧,并用于视频的帧级别的裁剪。
spleeter:spleeter是一个源分离器。可以用于音频的分离,将人声、鼓、贝斯和其他声音分离开来,便于后续的声音处理。
librosa:librasa是一个用于音乐和音频分析的 python 包。可以用于提取音频的采样值、采样率、节拍时间点等信息。
AudioCraft:AudioCraft 是一个用于音频生成深度学习研究的 PyTorch 库。 其中它的 MusicGen 功能可以用于生成音乐。
AudioSegment:AudioSegment 可以用于音频文件的裁剪。
整体逻辑
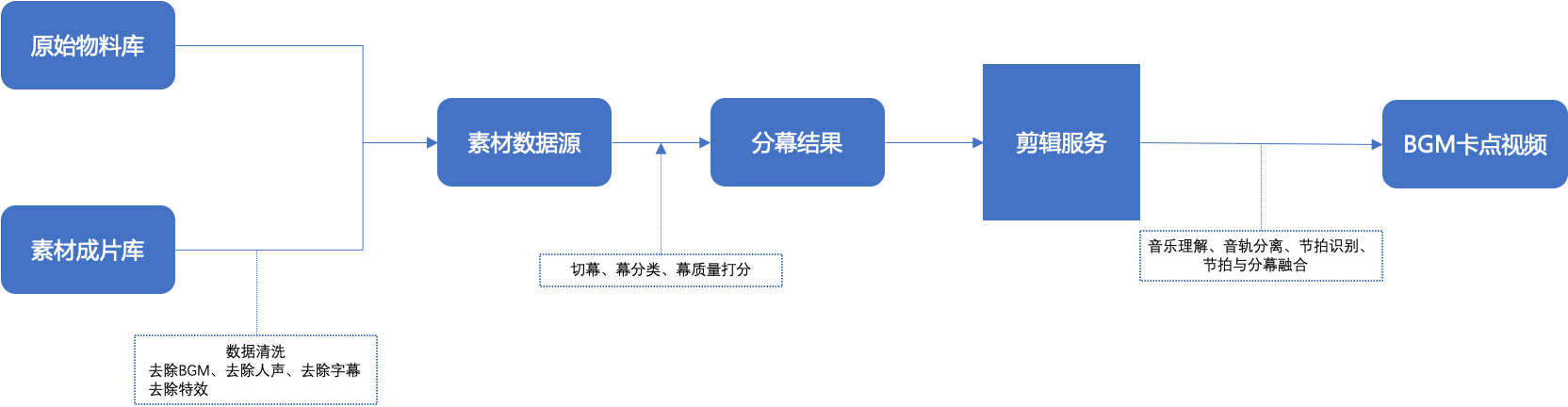
从整体逻辑看,整个流程不算复杂。共有如下几个步骤:
- 确定合适的数据源,也就是素材物料库,可以从原始物料中来,也可以从素材成片来。
- 离线将大量的视频做好切幕以及分类。
- 将上述分幕按照一定的规则导入到剪辑服务中。
- 剪辑服务输出成品卡点视频的地址,以供用户使用。
实现流程
BGM来自于成熟曲库
一般像剪映以及快影“剪同款”中的“卡点”功能就都算是BGM来自于成熟曲库。因为曲库中的音乐该在什么时刻进行卡点都已经是生成好了的。
后台需要做的事情仅就是将导入的多个视频裁剪为适合拼接的视频即可。这种卡点方式的实现流程比较简单。
- 接收用户传入的多个视频,此处校验视频时长是否满足需求。
- 导入音乐的卡点方案,这个卡点方案如果是时刻的数组,则可以使用 numpy 转为时间间隔的数组。如:将[1.345, 2.345, 3.456, 4.567, 5.678]转为[1.345, 1, 1.111, 1.111, 1.111]。便于后续视频的裁剪。
- 选择视频并进行视频裁剪,此处的视频可能是与卡点间隔一一对应的,也可能是随机或依据某个规则选择的。可以使用OpenCV进行视频裁剪,它可以实现帧级别的处理,非常适合卡点这种对时间要求较高的场景。
用OpenCV做视频裁剪的示例代码如下:
def video_stretch(input_file, output_file, dt):
cap = cv2.VideoCapture(input_file)
fps = cap.get(cv2.CAP_PROP_FPS)
(w, h) = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
# 读取 video
video = []
success = 1
while success:
success, frame = cap.read()
if success:
video.append(frame)
cap.release()
# 选择片段
frame_cnt = int(dt * fps)
new_fps = int(dt * fps) / dt
start = int((len(video) - frame_cnt) / 2)
sub_video = video[start:(start + frame_cnt)]
# 保存到新视频
vision_writer = cv2.VideoWriter(output_file, cv2.VideoWriter_fourcc(*'xvid'), new_fps, (w, h))
for frame in sub_video:
vision_writer.write(frame)
vision_writer.release()
这里裁剪的片段是取的中间的片段,实际上也可以在此处加入算法,判断从何处截取视频。
- 使用 ffmpeg 做视频的拼接,示例代码如下:
concat_cmd = "concat:" + "|".join(
[f"{workspaceMix}/bgm_stuck/tmp_ts/{scen_list_idx}_{i}.ts" for i in range(len(choose_list))])
cmd = 'ffmpeg -y -i \\"{concat_cmd}\\" -i "{audio_path}" -vcodec copy -absf aac_adtstoasc {output_file}'
os.system(cmd)
其中,{workspaceMix} 是剪辑机器上的工作空间。{scen_list_idx}_{i}.ts 是待拼接的视频片段。
ffmpeg 的拼接支持的比较简单,如果需要在视频间增加转场特效,还需要另外调用相应能力。
BGM来自于AI生成或用户上传
这种场景与上述BGM来自于成熟曲库的场景相比,多了一个在音乐中标记卡点时刻的步骤。而这一步的实现还是比较有挑战的,如果标记的不合理,那么最终呈现出的卡点效果就会很差。目前看起来剪映和快影还没有支持该功能,或许也是因为出片质量不是很好保障吧。
这里仅介绍一下AI音乐生成以及对应音乐的卡点时刻标记。用户上传音乐场景类似。
- AI生成音乐使用的是 AudioCraft 的 MusicGen 功能,我们只需要输入一段 Prompt,就可以得到相应的音乐。比如,我用的Prompt为:cheerful music without drums。可以得到如下音乐:
- 利用 Separator 将音乐做音轨分离,提取出音乐的纯粹节拍部分。代码如下:
sp = Separator(params_descriptor="spleeter:4stems")
sp.separate_to_file(orig_path, music_ai_path, codec="wav")
其中,参数params_descriptor="spleeter:4stems"表示将该段音频分离为人声、鼓、贝斯和其他声音。spleeter 还有一些别的参数可供选择。详细可参考:https://research.deezer.com/projects/spleeter.html
- 使用 librosa 加载鼓点音频文件,并获取到对应的音频时序数组以及采样率。代码如下:
drums, sampling_rate = librosa.load(drum_path)
其中,drum_path 是鼓点音频文件的路径,drums和sampling_rate分别表示音频时序数组以及采样率,示例分别为:[0.0012345, 0.0023456, 0.0034567, …] 和 44100。
- 使用 librosa 获取鼓点音频的节拍时刻。代码如下:
estimated_bpm, beats = librosa.beat.beat_track(y=drums, sr=sampling_rate, units='time')
其中drums和sampling_rate分别表示前面获取到的音频时序数组以及采样率。units 表示节拍位置的单位,可选time和frames,time 表示以时间为单位,frames 表示以帧数为单位。
estimated_bpm表示估计的全局节奏,以每分钟节拍为单位。beats是节拍时刻的数组。
librosa.beat.beat_track 具体的检测算法可以参考文档:http://labrosa.ee.columbia.edu/projects/beattrack/
- 使用 librosa 获取得到脉冲信号所在帧,使用上述 beats 计算得到节奏所在帧,并将脉冲信号所在帧与节奏所在帧进行匹配,得到节奏点。代码如下:
# 获取得到脉冲信号所在帧
onset_env = librosa.onset.onset_strength(y=y, sr=sr, hop_length=512, aggregate=np.median)
peaks = librosa.util.peak_pick(onset_env, 1, 1, 1, 1, 0.8, 5)
# 创建一个节拍值1/4、2/4、3/4、4/4的数组
M = beats * [[1 / 4], [2 / 4], [3 / 4]]
M = M.flatten()
M = np.sort(M)
# 局部脉冲与节拍点做10%的去误差,得到节奏点
L = []
for i in M:
for j in peaks:
if i * 0.9 < j < i * 1.1:
L.append(j)
L = list(set(L))
L.sort()
# 取前20个点,不够20个则全取
if len(L) > 20:
point_list = librosa.frames_to_time(L[:20], sr=sr)
else:
point_list = librosa.frames_to_time(L[:len(L)], sr=sr)
这里我们有个假设,就是AI生成或用户上传的音乐一定是2/4拍或3/4拍或4/4拍中的一种。这样才能通过该方法来找到节奏点。最终输出的节奏点是以脉冲信号为准的,因为有可能音乐的节奏点没有脉冲信号,我们要的卡点时刻一定是要有脉冲信号的。
librosa.util.peak_pick 的具体检测算法可以参考文档:https://librosa.org/doc/main/generated/librosa.util.peak_pick.html
- 使用AudioSegment 进行音频文件的裁剪,具体怎么裁剪这个就看业务需求了,参考代码如下:
# 音乐裁剪,设置开始结束时间
end_time = point_list[len(point_list) - 1] + start_time
start_time = start_time * 1000
end_time = end_time * 1000
sound = AudioSegment.from_mp3(music_path)
word = sound[start_time:end_time]
# 音乐储存路径
word.export('movie/music.wav', format="wav")
- 将节奏点时刻数组作为卡点方案,以及待剪辑的视频作为输入。这样后续的流程就和“BGM来自于成熟曲库”的流程一样了。
总结
本文总结了如何利用一些开源工具快速的实现视频素材BGM卡点的功能。限于篇幅,有很多细节都没有涉及到,比如更多酷炫转场的实现、相似素材场景聚类的实现等。后续如果有机会,会继续续写分享。
相关参考资料
OpenCV文档:https://docs.opencv.org/4.x/d9/df8/tutorial_root.html
spleeter:https://research.deezer.com/projects/spleeter.html
librosa:https://librosa.org/doc/latest/index.html
AudioCraft:https://audiocraft.metademolab.com/
AudioSegment:https://pydub.com/