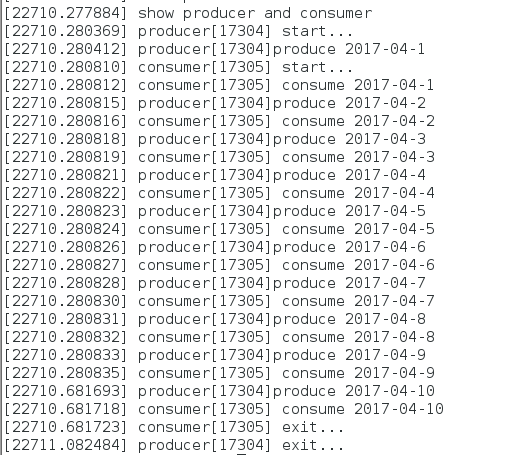
一、背景
ext4文件系统用的是jbd2日志系统。本篇博客从内核源码着手,大致分析jbd2日志系统。
二、源码分析
我这里用的是source insight工具来分析linux内核的源码。
内核版本为3.10.0。
首先我们搜索一下jbd2关键字。可以看到如下图所示: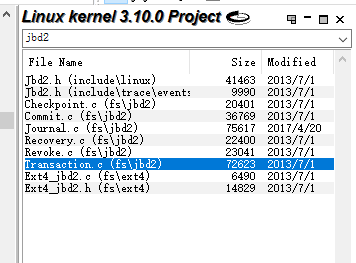
可以看到,在fs/jbd2中存在6个文件。这个fs/jbd2中存的就是jbd2日志系统的代码。
一步一步来,先看看插入jbd2模块时系统做了什么工作。
插入模块的函数在Journal.c中被定义。位于2611-2640行。
(这个图片下面经常要用到,用到时记得往回翻看!)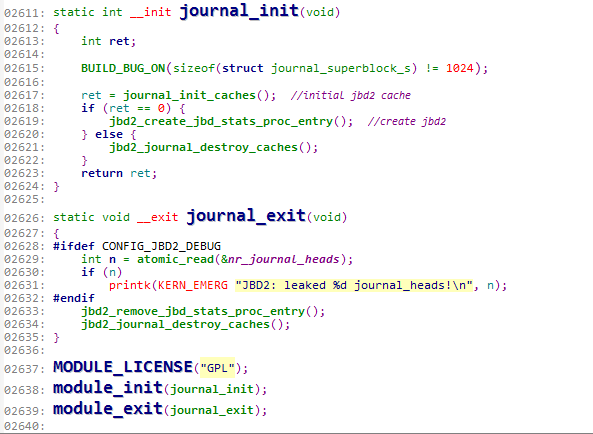
插入模块时运行的是journal_init函数,退出模块时运行的是journal_exit函数。我们先来看看插入模块时初始化函数journal_init做了什么。
第2615行:
宏定义检查journal_superblock_s结构体的大小是否等于1024字节。
若不等于1024字节,就会报错。
可以进入这个结构体看看,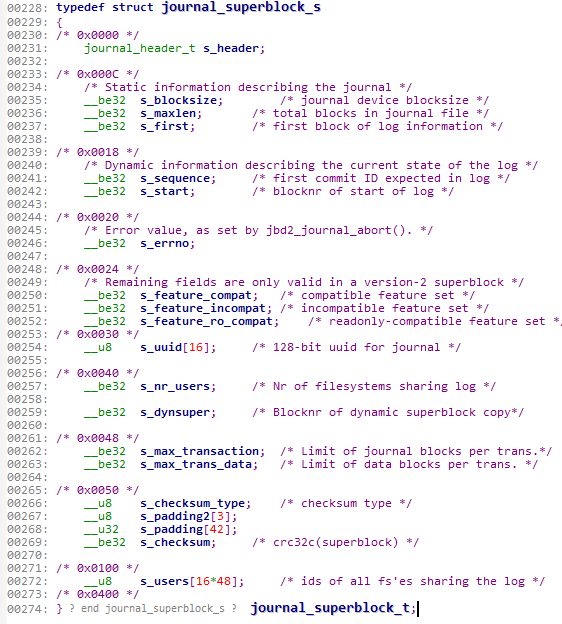
0x0400的大小表示这个结构体就是1024字节。如果这个结构体不是1024字节难道不该报错么?
这个结构体应该表示的是日志系统的固有属性。
第2617行:
journal_init_caches()函数
初始化日志所要用到的缓冲区,看看这个函数。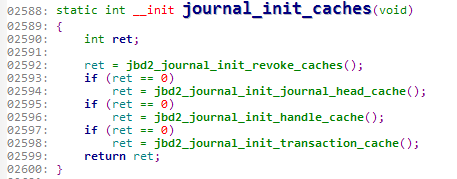
这个函数中调用了四个函数,都是用来初始化cache的。
分别为:
revoke_cache
head_cache
handle_cache
transaction_cache
以revoke_cache为例,我们看看它的函数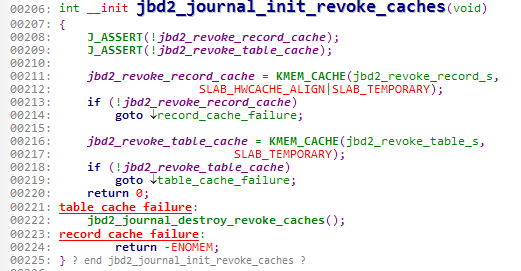
208-209:
断言jbd2_revoke_record_cache和jbd2_revoke_table_cache一定是空的。非空则报错。
211:
给revoke_record创建cache,使用SLAB分配机制。
213:
创建cache失败则跳到222销毁revoke_cache。
216:
给revoke_table创建cache,使用SLAB分配机制。
218:
创建cache失败则跳到224返回错误信息。
接下来我们回到journal_init函数继续来讲插入journal模块时运行的函数
这个时候假设cache已经创建成功了。会给ret返回0
接下来运行的就是jbd2_create_jbd_stats_proc_entry函数。
2619(往上翻我刚才说的那个图)
这个函数用来在/proc/fs下创建jbd2目录。jbd2用来存储日志的状态信息。
至于这些状态信息从哪里来的以后再说。这里只是创建了这个目录。
我们可以具体的看一下这些源码: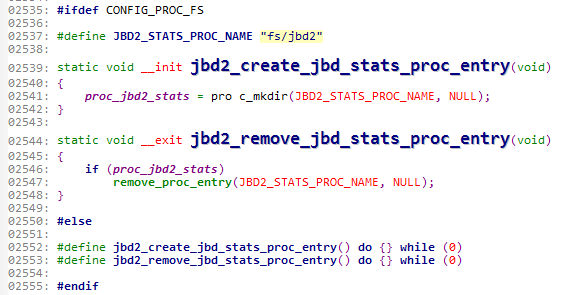
我们可以看到有两个jbd2_create_jbd_stats_proc_entry函数
一个是在/pro/fs下创建jbd2,一个是空循环函数。看2535、2550、2555可以知道这是内核中常用到的条件编译。#ifdef CONFIG_PROC_FS表示如果proc文件系统则编译下面的这段代码,否则,没有/proc目录,那么肯定也就无法创建jbd2,则执行空循环函数。
好了,接着讲journal_init函数。
之前我们说到,如果返回的ret等于0则表示初始化cache成功,接着会创建目录,那如果ret不等于0,也就是说cache的初始化失败了呢?(忘了ret是干吗的可以翻看前面第2个图片的代码)
这时就会执行jbd2_journal_destroy_caches函数
2621(往上翻我刚才说的那个图)
很明显,这个函数是用来销毁cache的,也就是说,cache创建失败了,那么严谨起见,不能就这么退出了,要先将cache销毁掉再报错。
看下该函数: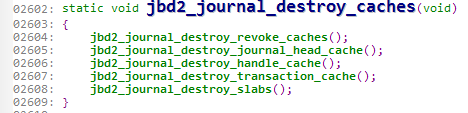
之前创建的四个cache在这里都要被销毁。那么,最后一个destroy_slabs函数是干什么的呢?我们可以进入这个函数看一下究竟。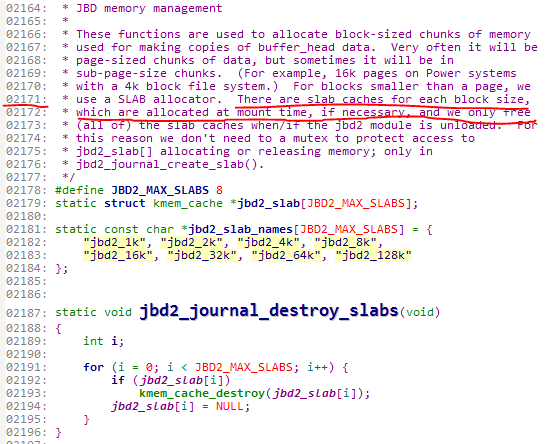
为什么我连着上面一大段解释也要截图出来呢?是因为仅仅看此函数是看不出来究竟的。大家可以阅读上面的解释,那么此函数的作用就一目了然。
2171行可以看到,这些cache是在挂载时开辟出来的,用于复制缓冲区的数据。而在jbd2卸载时这些cache将被释放。也就是这个函数用来释放这些cache。
journal_init函数解释到这里先告一段落。
接下来我们看一下卸载模块时运行的函数journal_exit。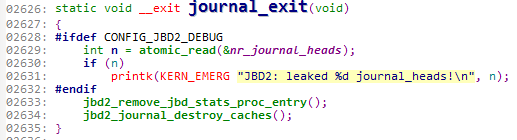
这里有一个条件编译,如果是JBD2的调试模式运行2629-2631,否则只运行其余部分。endif后面的代码就不用过多解释了,也就是删除目录与刚才讲过的cache的销毁。
2628
这段代码表示编译时是JBD2的调试模式。
2629
这是对nr_journal_heads的一个读原子操作。
我们看看这个变量。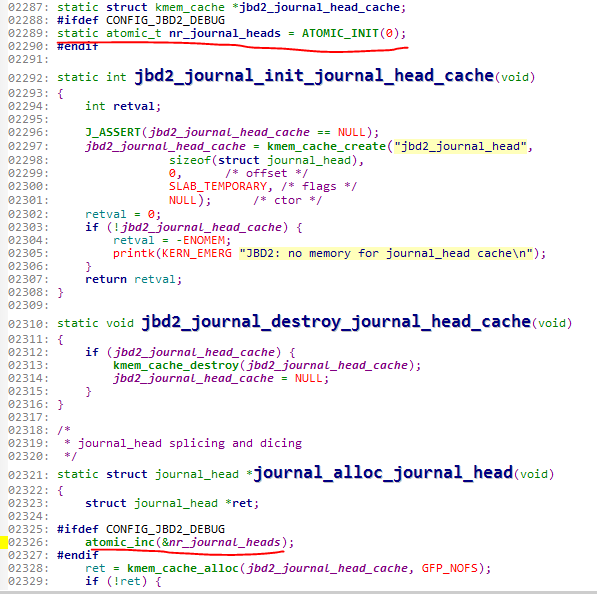
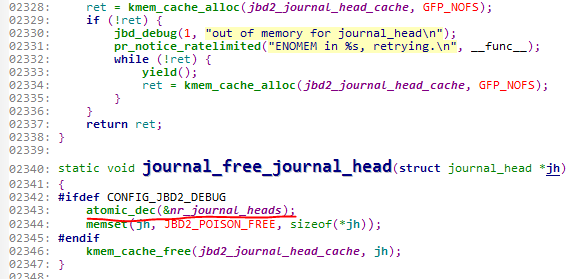
2289行定义了这个变量是原子变量,初值为0
2326行表明,如果分配了一次journal_head,那么就会对它进行原子操作加1
2343行表明,如果释放了一次journal_head,那么就会对它进行原子操作减1
之前提过journal_head_cache,以后再细讲。
2631
这段代码表明,JBD2日志系统泄漏了n个journal_head。n是上面从nr_journal_heads中读出的数值。
三、总结
到这里jbd2模块装载与卸载时做了什么也就大致分析完了。接下来的博客会继续分析ext4的日志系统。