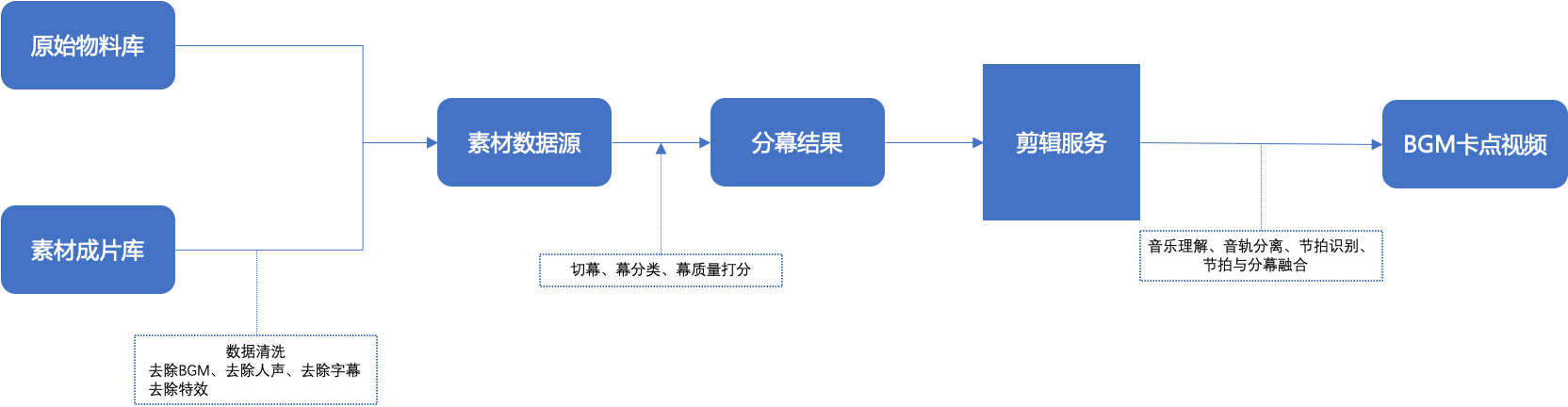
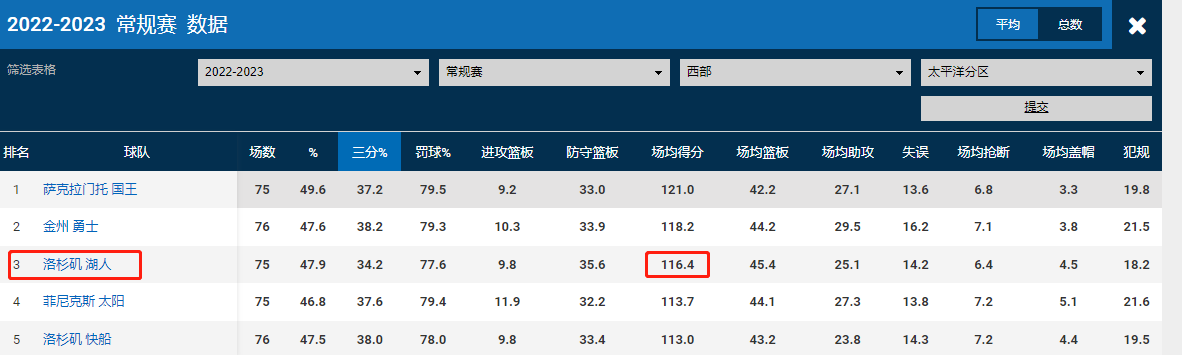
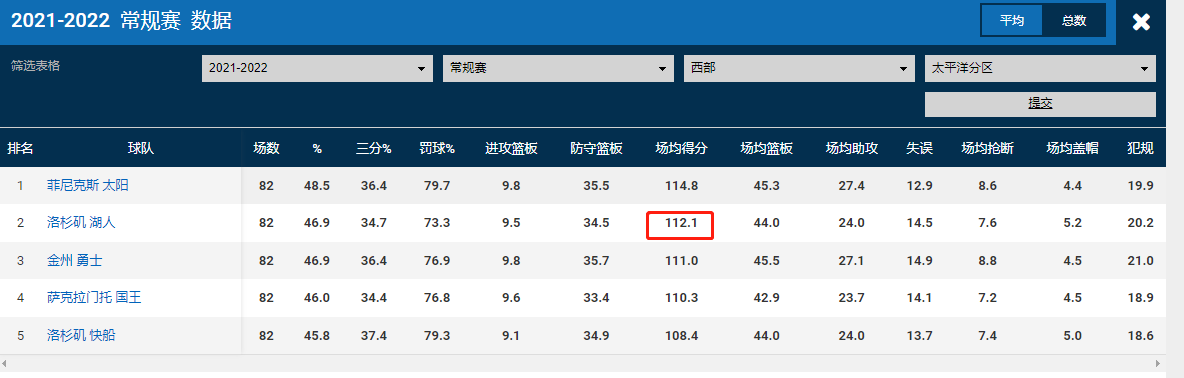
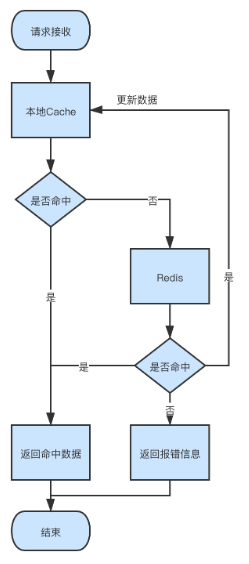
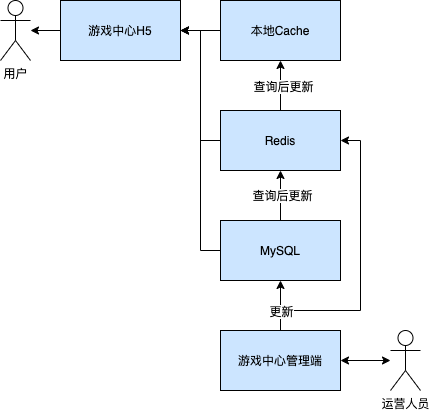
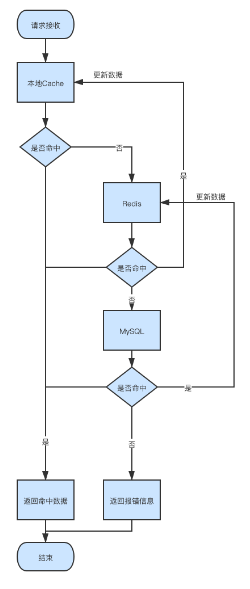
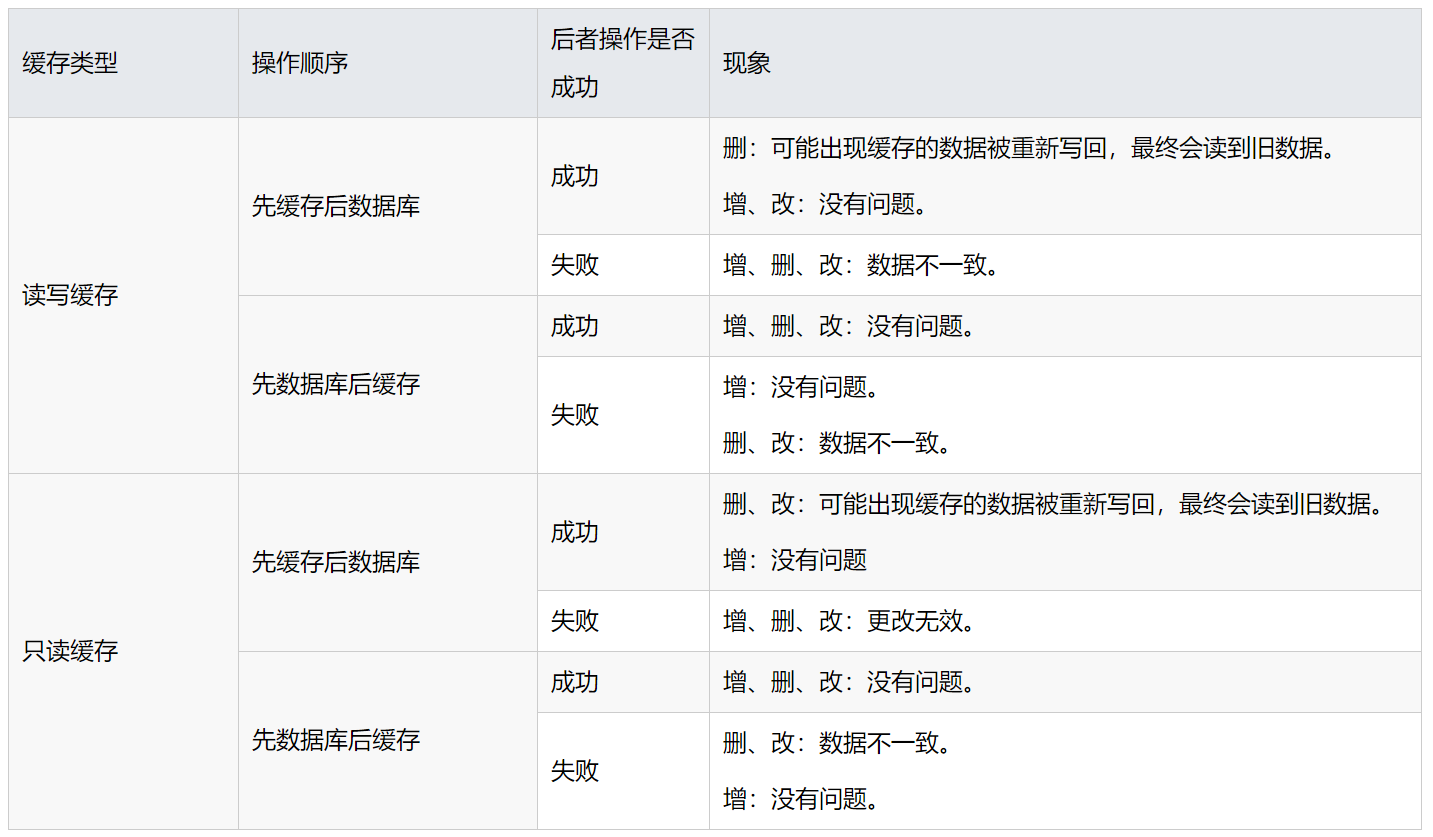
背景
最近想找一些用Go语言实现的优秀开源项目学习一下,etcd作为一个被广泛应用的高可用、强一致性服务发现存储仓库,非常值得分析学习。
本篇文章主要是对etcd的后台存储源码做一解析,希望可以从中学到一些东西。
etcd大版本区别
目前etcd常用的是v2和v3两个大版本。两个版本不同之处主要在于:
- v2版本仅在内存中对数据进行了存储,没有做持久化存储。而v3版本做了持久化存储,且还使用了缓存机制加快查询速度。
- v2版本和v3版本对外提供的接口做了一些改变。在命令行界面中,可以使用环境变量
ETCDCTL_API来设置对外接口。
我们在这里主要是介绍v3版本的后台存储部分实现。 并且这里仅涉及到底层的读写操作接口,并不涉及到更上层的读写步骤(键值的revision版本选择等)。
etcd的后端存储接口
分析思路:
- 查看etcd封装的后端存储接口
- 查看etcd实现了后端存储接口的结构体
- 查看上述结构体的初始化方法
- 查看上述结构体的初始化值
- 查看上述结构体初始化方法的具体初始化过程
首先,我们先来看下etcd封装的后端存储接口:
路径:https://github.com/etcd-io/etcd/blob/master/mvcc/backend/backend.go
type Backend interface {
// ReadTx returns a read transaction. It is replaced by ConcurrentReadTx in the main data path, see #10523.
ReadTx() ReadTx
BatchTx() BatchTx
// ConcurrentReadTx returns a non-blocking read transaction.
ConcurrentReadTx() ReadTx
Snapshot() Snapshot
Hash(ignores map[IgnoreKey]struct{}) (uint32, error)
// Size returns the current size of the backend physically allocated.
// The backend can hold DB space that is not utilized at the moment,
// since it can conduct pre-allocation or spare unused space for recycling.
// Use SizeInUse() instead for the actual DB size.
Size() int64
// SizeInUse returns the current size of the backend logically in use.
// Since the backend can manage free space in a non-byte unit such as
// number of pages, the returned value can be not exactly accurate in bytes.
SizeInUse() int64
// OpenReadTxN returns the number of currently open read transactions in the backend.
OpenReadTxN() int64
Defrag() error
ForceCommit()
Close() error
}
Backend接口封装了etcd后端所提供的接口,最主要的是:
ReadTx(),提供只读事务的接口,以及BatchTx(),提供读写事务的接口。
Backend作为后端封装好的接口,而backend结构体则实现了Backend接口。
路径:https://github.com/etcd-io/etcd/blob/master/mvcc/backend/backend.go
type backend struct {
// size and commits are used with atomic operations so they must be
// 64-bit aligned, otherwise 32-bit tests will crash
// size is the number of bytes allocated in the backend
// size字段用于存储给后端分配的字节大小
size int64
// sizeInUse is the number of bytes actually used in the backend
// sizeInUse字段是后端实际上使用的内存大小
sizeInUse int64
// commits counts number of commits since start
// commits字段用于记录启动以来提交的次数
commits int64
// openReadTxN is the number of currently open read transactions in the backend
// openReadTxN存储目前读取事务的开启次数
openReadTxN int64
// mu是互斥锁
mu sync.RWMutex
// db表示一个boltDB实例,此处可以看到,Etcd默认使用Bolt数据库作为底层存储数据库
db *bolt.DB
// 用于读写操作
batchInterval time.Duration
batchLimit int
batchTx *batchTxBuffered
// 该结构体用于只读操作,Tx表示transaction
readTx *readTx
stopc chan struct{}
donec chan struct{}
// 日志信息
lg *zap.Logger
}
通过19行 db *bolt.DB 我们可以看到,etcd的底层存储数据库为BoltDB。
好了,接下来我们就看一下这个backend结构体是如何初始化的。
还是在该路径下,我们可以看到New函数
// 创建一个新的backend实例
func New(bcfg BackendConfig) Backend {
return newBackend(bcfg)
}
该函数传入了参数bcfg,类型为BackendConfig,这是后端存储的配置信息。
我们先看下这个配置信息中包含了什么
依然在该路径下,找到BackendConfig结构体
type BackendConfig struct {
// Path is the file path to the backend file.
Path string
// BatchInterval is the maximum time before flushing the BatchTx.
// BatchInterval表示提交事务的最长间隔时间
BatchInterval time.Duration
// BatchLimit is the maximum puts before flushing the BatchTx.
BatchLimit int
// BackendFreelistType is the backend boltdb's freelist type.
BackendFreelistType bolt.FreelistType
// MmapSize is the number of bytes to mmap for the backend.
// MmapSize表示分配的内存大小
MmapSize uint64
// Logger logs backend-side operations.
Logger *zap.Logger
// UnsafeNoFsync disables all uses of fsync.
UnsafeNoFsync bool `json:"unsafe-no-fsync"`
}
可以看到,有许多backend初始化所需要的信息都在这个结构体中。
既然有这些配置信息,那么一定会有相应的默认配置信息,
我们来看下在默认情况下etcd存储部分会被赋怎样的值。
依然在该目录下,找到DefaultBackendConfig函数。
func DefaultBackendConfig() BackendConfig {
return BackendConfig{
BatchInterval: defaultBatchInterval,
BatchLimit: defaultBatchLimit,
MmapSize: initialMmapSize,
}
}
随便查看其中某个全局变量的值,比如defaultBatchInterval,则可以看到默认值:
var (
defaultBatchLimit = 10000
defaultBatchInterval = 100 * time.Millisecond
defragLimit = 10000
// initialMmapSize is the initial size of the mmapped region. Setting this larger than
// the potential max db size can prevent writer from blocking reader.
// This only works for linux.
initialMmapSize = uint64(10 * 1024 * 1024 * 1024)
// minSnapshotWarningTimeout is the minimum threshold to trigger a long running snapshot warning.
minSnapshotWarningTimeout = 30 * time.Second
)
以defaultBatchInterval变量为例,就是说默认情况下,etcd会100秒做一次自动的事务提交。
etcd后端存储默认赋值的部分说完了,就说回对结构体的初始化上。
我们继续看函数New,它调用了函数newBackend,
我们看下函数newBackend做了些什么
func newBackend(bcfg BackendConfig) *backend {
if bcfg.Logger == nil {
bcfg.Logger = zap.NewNop()
}
// 一些配置载入
bopts := &bolt.Options{}
if boltOpenOptions != nil {
*bopts = *boltOpenOptions
}
bopts.InitialMmapSize = bcfg.mmapSize()
bopts.FreelistType = bcfg.BackendFreelistType
bopts.NoSync = bcfg.UnsafeNoFsync
bopts.NoGrowSync = bcfg.UnsafeNoFsync
// 初始化Bolt数据库
db, err := bolt.Open(bcfg.Path, 0600, bopts)
if err != nil {
bcfg.Logger.Panic("failed to open database", zap.String("path", bcfg.Path), zap.Error(err))
}
// In future, may want to make buffering optional for low-concurrency systems
// or dynamically swap between buffered/non-buffered depending on workload.
// 对backend结构体做初始化,包括了readTx只读事务以及batchTx读写事务
b := &backend{
db: db,
batchInterval: bcfg.BatchInterval,
batchLimit: bcfg.BatchLimit,
readTx: &readTx{
baseReadTx: baseReadTx{
buf: txReadBuffer{
txBuffer: txBuffer{make(map[string]*bucketBuffer)},
},
buckets: make(map[string]*bolt.Bucket),
txWg: new(sync.WaitGroup),
txMu: new(sync.RWMutex),
},
},
stopc: make(chan struct{}),
donec: make(chan struct{}),
lg: bcfg.Logger,
}
b.batchTx = newBatchTxBuffered(b)
// 开启一个新的etcd后端存储连接
go b.run()
return b
}
我们可以看到6-19行在初始化boltDB的同时载入了一些数据库的配置信息。
23-41行是对backend结构体做了初始化,包括了只读事务readTx、读写事务batchTx结构体的初始化,以及初始化了两个通道stopc、donec,这个后面会用到。
43行开启了一个协程去并发的处理run()函数内的工作。
我们继续看一下run()函数做了什么。依然在该目录下
func (b *backend) run() {
// 关闭结构体的donec通道
defer close(b.donec)
// 开启一个定时器
t := time.NewTimer(b.batchInterval)
// 最后要关闭定时器
defer t.Stop()
for {
select {
// 当定时器到时间了,则t.C会有值
case <-t.C:
case <-b.stopc:
b.batchTx.CommitAndStop()
return
}
// 定时器到时间了,且数据的偏移量非0,即有数据的情况下,则会进行一次事务的自动提交
if b.batchTx.safePending() != 0 {
b.batchTx.Commit()
}
// 重新设置定时器的时间
t.Reset(b.batchInterval)
}
}
我在代码中注释的比较详细了,简单的说,就是在初始化backend结构体时,开启了一个协程用于事务的自动提交,事务自动提交的时间间隔为batchInterval,这个默认值为100秒。
注意12-14行,这段代码表示,如果是停止信号进来的话,则事务会立即提交并且停止。
到这里,backend结构体就初始化完成了,接下来我们看一下用于读操作的只读事务接口ReadTx
etcd后端存储的读操作
路径:https://github.com/etcd-io/etcd/blob/master/mvcc/backend/read_tx.go
type ReadTx interface {
Lock()
Unlock()
RLock()
RUnlock()
UnsafeRange(bucketName []byte, key, endKey []byte, limit int64) (keys [][]byte, vals [][]byte)
UnsafeForEach(bucketName []byte, visitor func(k, v []byte) error) error
}
该接口是用结构体baseReadTx实现的,来看一下baseReadTx结构体,文件路径与ReadTx接口一样
type baseReadTx struct {
// buf与buckets都是用于增加读效率的缓存
// mu用于保护txReadBuffer缓存的操作
mu sync.RWMutex
buf txReadBuffer
// txMu用于保护buckets缓存和tx的操作
txMu *sync.RWMutex
tx *bolt.Tx
buckets map[string]*bolt.Bucket
// txWg可以防止tx在批处理间隔结束时回滚,直到使用该tx完成所有读取为止
txWg *sync.WaitGroup
}
只读事务ReadTx的读取数据的接口有两个,分别是UnsafeRange以及UnsafeForEach。我们以UnsafeRange接口为例进行代码分析。
UnsafeRange接口的实现依然在上述路径中
// 该方法用于底层数据的只读操作
func (baseReadTx *baseReadTx) UnsafeRange(bucketName, key, endKey []byte, limit int64) ([][]byte, [][]byte) {
// 不使用范围查询
if endKey == nil {
// forbid duplicates for single keys
limit = 1
}
// 当范围值异常时,则传入最大范围
if limit <= 0 {
limit = math.MaxInt64
}
if limit > 1 && !bytes.Equal(bucketName, safeRangeBucket) {
panic("do not use unsafeRange on non-keys bucket")
}
// 将buf缓存中的数据读取出来
keys, vals := baseReadTx.buf.Range(bucketName, key, endKey, limit)
// 如果取出的数据满足了需求,那么则直接返回数据
if int64(len(keys)) == limit {
return keys, vals
}
// find/cache bucket
// 从bucket缓存中查询bucket实例,查询到了则返回缓存中的实例,查询不到,则在BoltDB中查找
bn := string(bucketName)
baseReadTx.txMu.RLock()
bucket, ok := baseReadTx.buckets[bn]
baseReadTx.txMu.RUnlock()
lockHeld := false
// 缓存中取不到bucket的话,会从bolt中查找,并写入缓存中
if !ok {
baseReadTx.txMu.Lock()
lockHeld = true
bucket = baseReadTx.tx.Bucket(bucketName)
baseReadTx.buckets[bn] = bucket
}
// ignore missing bucket since may have been created in this batch
if bucket == nil {
if lockHeld {
baseReadTx.txMu.Unlock()
}
return keys, vals
}
if !lockHeld {
baseReadTx.txMu.Lock()
lockHeld = true
}
c := bucket.Cursor()
baseReadTx.txMu.Unlock()
// 从bolt的该bucket中查找键值对
k2, v2 := unsafeRange(c, key, endKey, limit-int64(len(keys)))
return append(k2, keys...), append(v2, vals...)
}
4-14行是一些前置的判断步骤,16-20则是从buf缓存中读取数据,前面提到过,buf是etcd用于提高读取效率的缓存。
我们看下具体的从buf读取数据的过程。
Range函数在路径:https://github.com/etcd-io/etcd/blob/master/mvcc/backend/tx_buffer.go
func (txr *txReadBuffer) Range(bucketName, key, endKey []byte, limit int64) ([][]byte, [][]byte) {
if b := txr.buckets[string(bucketName)]; b != nil {
return b.Range(key, endKey, limit)
}
return nil, nil
}
可以看到,该方法就是实例化了名为bucketName的桶,然后从该桶中按照范围读取键值数据。
我们可以看到,bucket的实例为结构体bucketBuffer
type bucketBuffer struct {
buf []kv
// used字段记录了正在使用的元素个数,这样buf无需重新分配内存就可以覆盖写入
used int
}
看回到Range方法代码的第3行,我们来看一下b.Range方法的代码。b.Range与buf.Range方法不同,b.Range是结构体bucketBuffer实现的方法。
依然与Range方法相同路径
func (bb *bucketBuffer) Range(key, endKey []byte, limit int64) (keys [][]byte, vals [][]byte) {
// 查找到key在buf中的索引idx
f := func(i int) bool { return bytes.Compare(bb.buf[i].key, key) >= 0 }
// sort.Search用于从某个切片中查找某个值的索引
idx := sort.Search(bb.used, f)
if idx < 0 {
return nil, nil
}
// 只查找一个key值,而非范围查找
if len(endKey) == 0 {
if bytes.Equal(key, bb.buf[idx].key) {
keys = append(keys, bb.buf[idx].key)
vals = append(vals, bb.buf[idx].val)
}
return keys, vals
}
// 根据字节的值来比较字节切片的大小
// 如果endKey比key值小,则返回nil
if bytes.Compare(endKey, bb.buf[idx].key) <= 0 {
return nil, nil
}
// 在个数限制limit内,且小于endKey的所有键值对都取出来
for i := idx; i < bb.used && int64(len(keys)) < limit; i++ {
if bytes.Compare(endKey, bb.buf[i].key) <= 0 {
break
}
keys = append(keys, bb.buf[i].key)
vals = append(vals, bb.buf[i].val)
}
return keys, vals
}
3-5行代码表示要从buf结构体中找到第一个满足包含key的索引值。该两行代码一般结合使用,是一种常见的用于查找值对应索引值的方式。
10-16行代码表示,如果endKey为0,即不使用范围查找,只查找key这一个精确值,那么就需要判断3-5代码找到的值是否与该key完全相等,只有完全相等了才会返回keys与vals。
19-21行代码表示,如果输入的endKey比key值还要小,那么就认为是输入的问题,则返回nil值。
最后19-30行代码表示,key与endKey都输入正常的情况下,则将limit内,大于等于key且小于endKey的键值对都取出来,并返回keys、vals结果。
到此,从buf缓存中就可以读取所需要的数据了,那么,我们回过头接着看UnsafeRange方法的实现,该方法在前面有提到。
我再次把代码贴在这里:
// 该方法用于底层数据的只读操作
func (baseReadTx *baseReadTx) UnsafeRange(bucketName, key, endKey []byte, limit int64) ([][]byte, [][]byte) {
// 不使用范围查询
if endKey == nil {
// forbid duplicates for single keys
limit = 1
}
// 当范围值异常时,则传入最大范围
if limit <= 0 {
limit = math.MaxInt64
}
if limit > 1 && !bytes.Equal(bucketName, safeRangeBucket) {
panic("do not use unsafeRange on non-keys bucket")
}
// 将buf缓存中的数据读取出来
keys, vals := baseReadTx.buf.Range(bucketName, key, endKey, limit)
// 如果取出的数据满足了需求,那么则直接返回数据
if int64(len(keys)) == limit {
return keys, vals
}
// find/cache bucket
// 从bucket缓存中查询bucket实例,查询到了则返回缓存中的实例,查询不到,则在BoltDB中查找
bn := string(bucketName)
baseReadTx.txMu.RLock()
bucket, ok := baseReadTx.buckets[bn]
baseReadTx.txMu.RUnlock()
lockHeld := false
// 缓存中取不到bucket的话,会从bolt中查找,并写入缓存中
if !ok {
baseReadTx.txMu.Lock()
lockHeld = true
bucket = baseReadTx.tx.Bucket(bucketName)
baseReadTx.buckets[bn] = bucket
}
// ignore missing bucket since may have been created in this batch
if bucket == nil {
if lockHeld {
baseReadTx.txMu.Unlock()
}
return keys, vals
}
if !lockHeld {
baseReadTx.txMu.Lock()
lockHeld = true
}
c := bucket.Cursor()
baseReadTx.txMu.Unlock()
// 从bolt的该bucket中查找键值对
k2, v2 := unsafeRange(c, key, endKey, limit-int64(len(keys)))
return append(k2, keys...), append(v2, vals...)
}
看第16-20行,刚才我们已经分析了16行代码的具体实现。
18-19行则表示,如果返回的key的数量与limit相等,则就直接返回缓存中的数据即可。如果不是相等的,一般取出的key的数量小于limit值,也就是说,缓存中的数据不完全满足我们的查询需求,那么则需要继续向下执行,到etcd的底层数据库bolt中查询数据。
注意24-43行,首先etcd会从baseReadTx结构体的buckets缓存中查询查询bucket实例,如果缓存中查询不到该实例,则会从bolt数据库中查询并且将实例写入到缓存中。而如果bolt中也查询不到该bucket,则会直接返回之前从buf中查询到的keys与vals值。
如果从缓存或者bolt中查询到了bucket实例,那么,后续就可以直接从bolt中查询该bucket下的键值对了。
我们看一下52行的具体实现。
func unsafeRange(c *bolt.Cursor, key, endKey []byte, limit int64) (keys [][]byte, vs [][]byte) {
if limit <= 0 {
limit = math.MaxInt64
}
var isMatch func(b []byte) bool
// 如果有终止的key,则将找到的key与终止的key比较,是否key小于endkey
// 否则,将找到的key与自身比较是否相等
if len(endKey) > 0 {
isMatch = func(b []byte) bool { return bytes.Compare(b, endKey) < 0 }
} else {
isMatch = func(b []byte) bool { return bytes.Equal(b, key) }
limit = 1
}
// 循环查找key所对应的值, 然后与endkey做对比(如果有endkey的话)
// 直到不满足所需条件
for ck, cv := c.Seek(key); ck != nil && isMatch(ck); ck, cv = c.Next() {
vs = append(vs, cv)
keys = append(keys, ck)
if limit == int64(len(keys)) {
break
}
}
return keys, vs
}
先看一下传入unsafeRange方法的参数。
c为cursor实例,key为我们要查询的初始key值,endkey为我们要查询的终止key值。而limit是我们查询的范围值,由于我们之前用缓存已经查询出来了一些数据,因此,该范围其实是我们的总范围减去已经查询到的key值数。
其中,5-13行代码用到了匿名函数,用于判断查询到的key值是否依然满足需求。如果我们给到了endkey,那么就会对查到的key与endkey做比较。如果我们没有给endkey,那么就会直接判断查询到的key值是否等于我们要查询的key。
17-23行则为用于DB查询实现代码。
etcd后端存储的写操作
文章开头部分,我们讲到过etcd后端存储对外的接口Backend,其中包括了两个重要的接口:ReadTx以及BatchTx,ReadTx接口负责只读操作,这个我们在前面已经讲到了。
接下来,我们看一下etcd后端存储的读写接口BatchTx。
路径:https://github.com/etcd-io/etcd/blob/master/mvcc/backend/batch_tx.go
type BatchTx interface {
ReadTx
UnsafeCreateBucket(name []byte)
UnsafePut(bucketName []byte, key []byte, value []byte)
UnsafeSeqPut(bucketName []byte, key []byte, value []byte)
UnsafeDelete(bucketName []byte, key []byte)
// Commit commits a previous tx and begins a new writable one.
Commit()
// CommitAndStop commits the previous tx and does not create a new one.
CommitAndStop()
}
我们可以看到,BatchTx接口也包含了前面讲到的ReadTx接口,以及其他用于写操作的方法。batchTx结构体实现了BatchTx接口。
type batchTx struct {
sync.Mutex
tx *bolt.Tx
backend *backend
// 数据的偏移量
pending int
}
具体接口中方法的实现我们就不一一看了,因为都是直接调用了bolt数据库的接口,比较简单。
总结
本篇文章主要从源码角度分析了etcd后端存储的底层读写操作的具体实现。无论我们是使用命令行操作etcd,还是调用etcd的对外接口。最终在对键值对进行读写操作时,底层都会涉及到今天分析的这两个接口:ReadTx以及BatchTx。
然而,etcd的键值对读写其实还会涉及到许多其他的知识,比如revision的概念。接下来还会有文章继续对这些知识做解析。