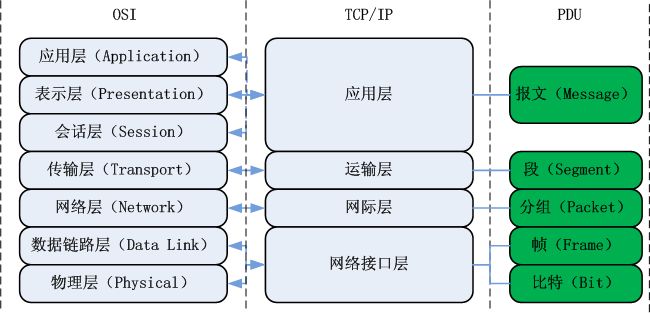
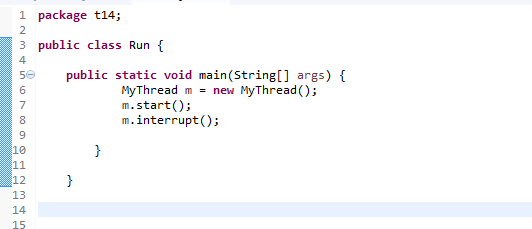
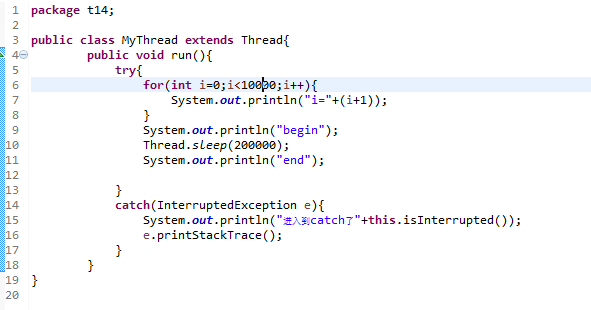
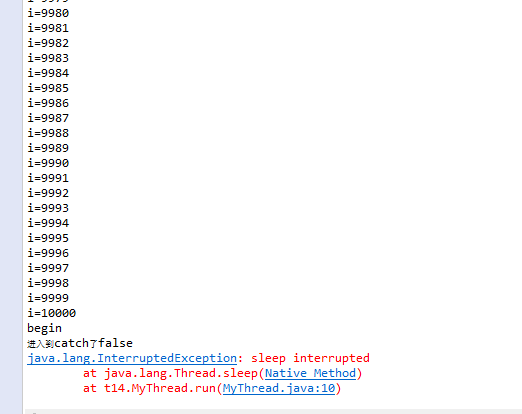
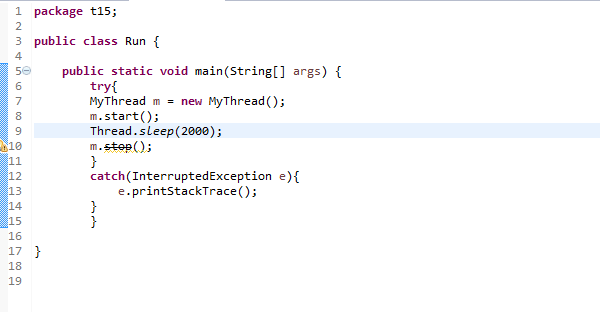
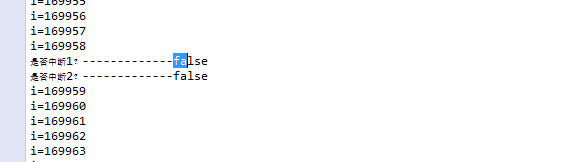一、背景
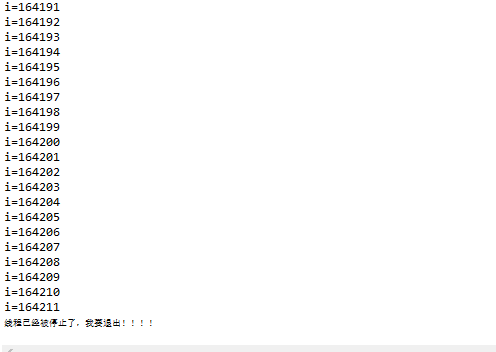
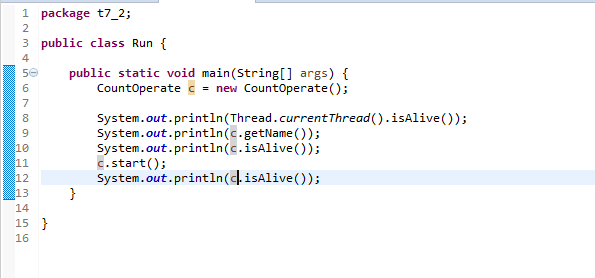
学习linux文件系统时考虑一个具体的问题:我们经常会用U盘传输东西到计算机中。当我们把U盘插入到一台计算机上,并且从U盘中复制文件到计算机里,然后卸载U盘,将U盘拔出。操作系统在这一连串过程中做了些什么?这篇博客仅从文件系统的角度利用linux内核源码浅析该过程。本篇博客使用的linux内核版本为3.10.0。
二、文件系统基础
1.文件系统
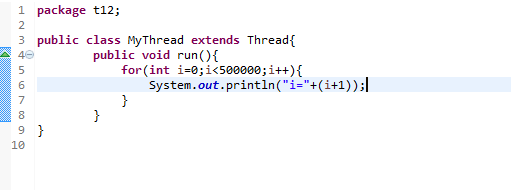
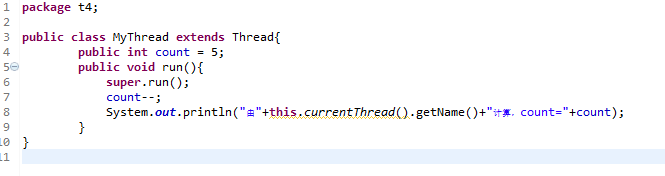
在开始之前我想先简单介绍一下文件系统的基础知识。
我们都知道,计算机磁盘被抽象成了一个个块设备,一个块作为一个存储单元。我的系统块大小为1KB,linux中可以使用df命令来查看块大小。
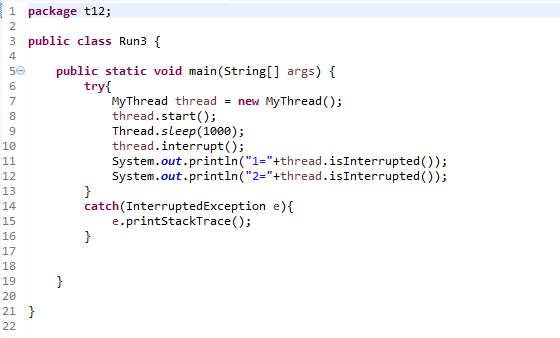
在块抽象上还有另一层抽象,主要由三部分组成:超级块、i节点表、数据块。每个部分都由若干的块来组成。当然,数据块占用最多的块。
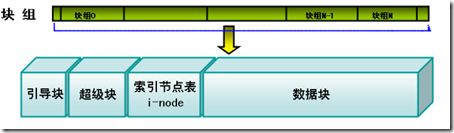
图中展示了这三个部分。其中引导块我不在这里详述。i节点也叫i-node,也可以叫做索引节点。叫法不同,实际指同一对象。
以EXT4文件系统为例,接下来我对这三个区域分别进行介绍:
超级块
超级块用来描述整个文件系统本身的信息。每个具体的文件系统如:EXT2、EXT3、EXT4、NTFS,它们都拥有自己的超级块。各自的超级块描述着各自文件系统的情况。
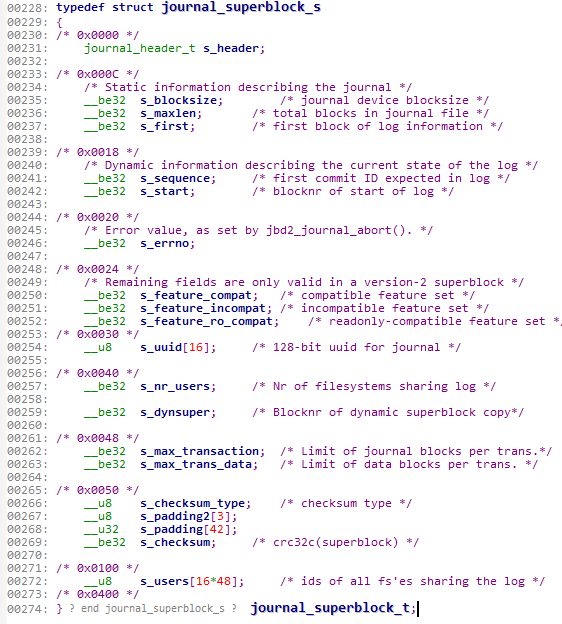
这里给大家展示EXT4文件系统的超级块在linux内核中的定义(部分):

EXT4文件系统的超级块定义存放在/fs/ext4文件夹下的ext4.h中
i节点
i节点存储于i节点表中。i节点中存储着大量的关于文件的重要信息,如文件的各种属性,文件的数据存储的位置等。
EXT4文件系统i节点在内核中的定义(部分):
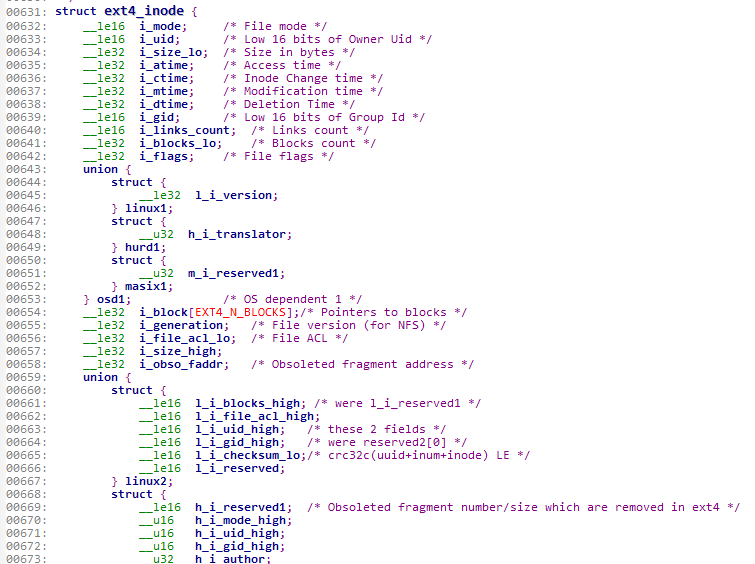
EXT4文件系统的i节点定义存放在/fs/ext4文件夹下的ext4.h中
数据区
数据区,顾名思义,存储的是文件的具体数据。每个文件占用多个块来进行存储。通过i节点来指向这些数据块的位置。
当一个文件“静静”的在磁盘上时,i节点用来描述这个文件,每个文件对应一个i节点号,这个i节点号之于文件就相当于身份证号之于我们公民。i节点中存储着关于文件的各种属性,并且i节点也描述了文件数据的存储位置。
那么,现在有个问题。
当我们打开一个文件,需要读取文件的属性或者文件的数据时操作系统是怎么做的?当然这个文件的信息需要被读取到内存中进行处理。首先,我们需要知道我们有没有权限打开这个文件,那么肯定就要查看该文件i节点中存储的属性信息。因为文件权限就是文件的一个属性。所以该文件的i节点的信息需要被读取到内存中。
各种不同的文件系统的文件都可能被操作系统打开,所以i节点信息都可能需要读取到内存中。面对不同的文件系统,操作系统如何进行统一的管理就成了问题。由此,操作系统引入了一种抽象的文件系统,这种抽象的文件系统可以用同一组系统调用对各种不同的文件系统以及文件进行操作。这种抽象的文件系统被称作虚拟文件系统。
2.虚拟文件系统(VFS)
虚拟文件系统相对于具体的如EXT2、EXT3、NTFS这样的文件系统不同之处在于“虚拟”二字。所以要理解虚拟文件系统,重点在于理解“虚拟”。
首先,虚拟文件系统在磁盘中是不占用存储空间的,它只活动于内存之中。对于一个具体的如EXT4文件系统,当用户需要使用该文件系统时就会将有关信息存入内存之中,即使用虚拟文件系统来进行操作。
如果内核要使用一个文件系统,第一步要做的是什么?当然是将该文件系统的超级块信息调入虚拟文件系统的超级块中。
VFS超级块
那么,我们来看一下虚拟文件系统中超级块的模样(部分):

这些信息存储在/include/linux/fs.h中,很明显,这个目录存储的不是某一具体的文件系统的信息。
之前我们说过,文件的i节点信息在未使用时“静静”的躺在磁盘中,当打开该文件,则需要使用相关信息。这时,文件的i节点信息会被调入内存中,填充的就是VFS的i节点。
VFS i节点
看一下虚拟文件系统中i节点结构的模样(部分):

这些信息同样存储在/include/linux/fs.h中。
dentry结构
实际上,一个文件除了被i节点描述,还被一个叫做dentry的结构所描述。在这里大家可能困惑,我之前说过一个文件是被一个i节点所描述的,这里却又说被一个dentry结构所描述,这不是自相矛盾了么?
实际上并不矛盾。我之前说文件被i节点描述指的是在具体的文件系统当中,指的是当文件“静静”躺在磁盘上时是被i节点所描述的。但对于虚拟文件系统,一个文件除了被i节点描述,还被dentry描述。而二者描述的角度是不同的。i节点描述了文件的固有属性,如文件大小、文件权限等。dentry描述了文件的逻辑属性,比如它的父目录是什么。
我们知道一个文件可以创建多个硬链接,硬链接的实质是不同的文件名指向同一个i节点,实际上这些不同的文件名的“本质”是一样的。所以,它们的i节点是相同的。然而,这些文件名可能处于不同的父目录中,那么它们的逻辑属性就不相同了,也就是说dentry是不同的。
对于i节点与dentry的区别,可以举个例子:
对于同一个出版社出版的某一图书,比如同济版的高数书,它有其固有属性如页数、版面大小、字数多少。对应i节点来描述。但同一本书可以出版多本,全国各地可能都有此书,那么,这些书分布的省份、书店、学校,这些就是逻辑属性。对应dentry来描述。
我们看一下dentry在内核中的定义:
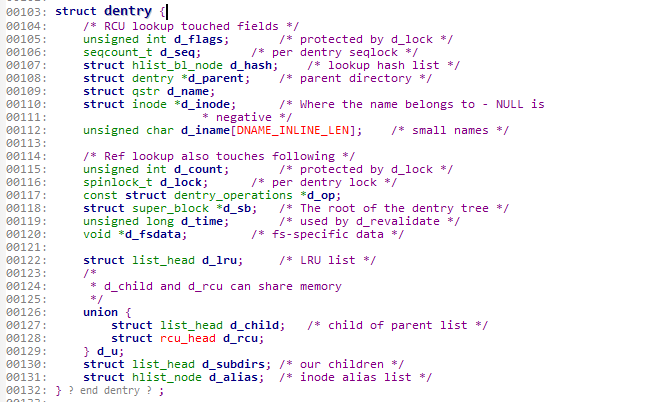
在i节点的结构体中,有一个dentry的链表。
实际上,一个i节点可以对应多个dentry。
file结构
file结构是文件对象,linux在file结构中保存了文件打开的位置,称为打开的文件描述。这是一个与进程相关的文件结构,许多进程打开文件时对于文件的描述在其中被定义。其中具体的定义可查看源码中的定义:
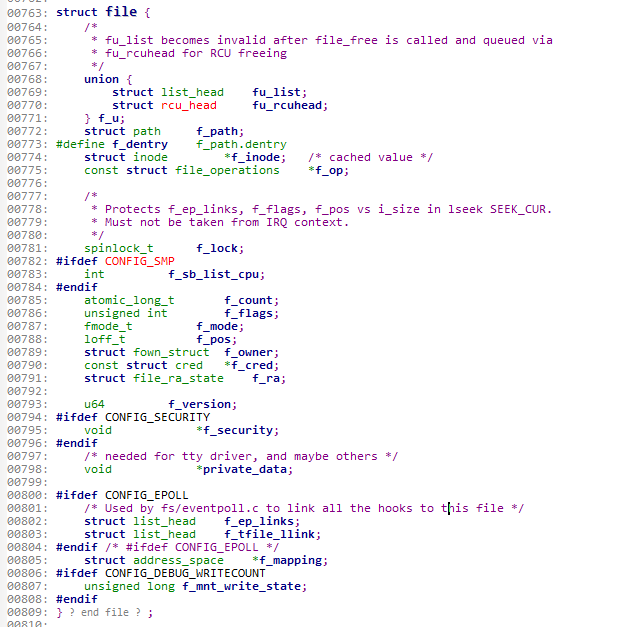
定义在/include/linux/Fs.h中。
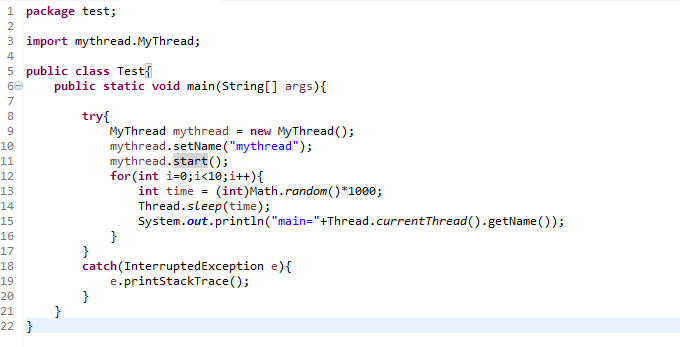
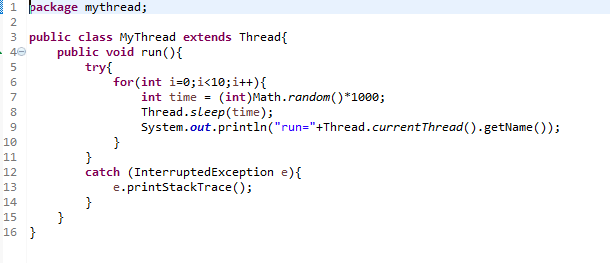
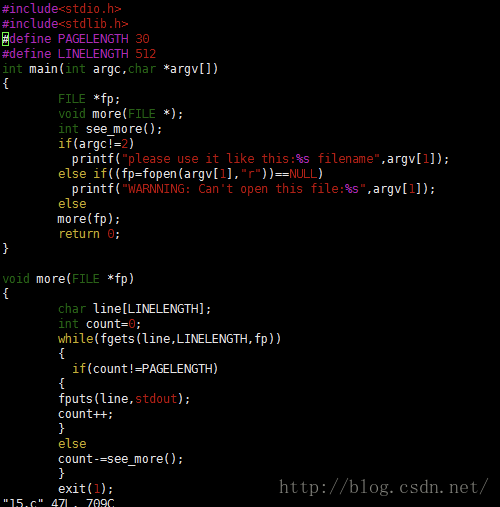
三、过程演示
使用mount命令
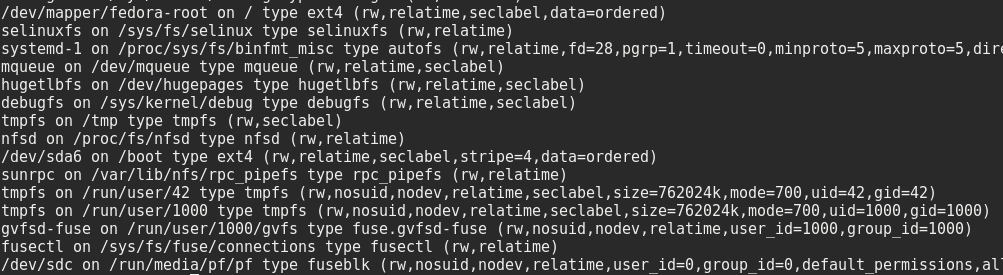
我们可以看到我的linux文件系统是EXT4,而U盘的文件系统是NTFS。
使用cp命令从U盘中复制一张图片到我的家目录下。

可以看到这个图片名叫0.png
结果当然是家目录下多了一个文件0.png

四、源码分析
上述演示过程看起来非常简单,只是使用cp命令指定一个文件和一个目录而已。
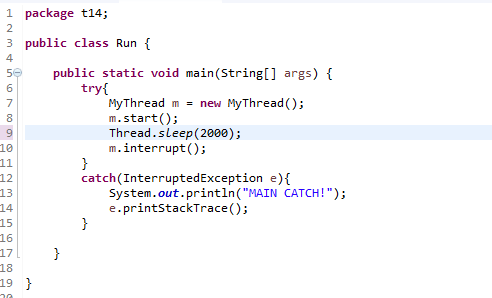
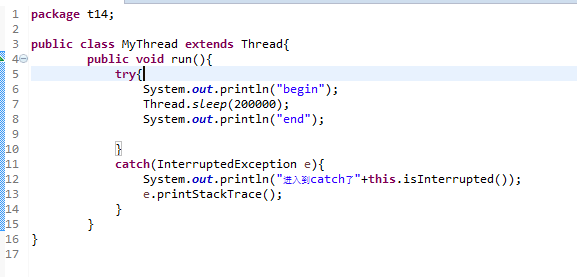
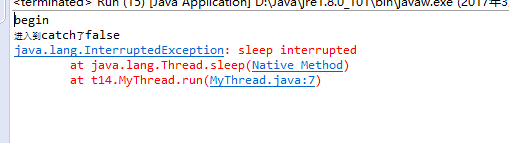
问题在于从我将U盘插入到传输数据再到我将U盘拔出。这期间操作系统做了哪些工作呢?
我的linux文件系统是EXT4,U盘的文件系统是NTFS。我们知道,我们将U盘插入计算机时,U盘会进行一个注册与安装的过程,也就是挂载。我的U盘挂载在了/run/media目录下。所以我的U盘的数据都可以从此文件夹下找到。
文件系统的注册、安装、卸载
那么,注册在源码中是如何实现的?
注册
内核在编译时就确定了其支持的文件系统,这些文件系统在系统启动时就在VFS中进行了注册。注册在内核中的实现是填写一个叫做file_system_type的结构体。该结构体中定义了文件系统类型名,文件系统特征,超级块的函数指针等。而且还定义了一个用于指向下一个file_system_type结构体的指针。

该结构体在/include/linux/fs.h中被定义。
如果需要安装的文件系统在linux中并没有注册呢?如果是内核可加载的模块,那么文件系统就会在实际安装的时候进行注册,而在卸载的时候进行注销。
实际上,该结构体的信息并不完整,我们都知道,要挂载一个文件系统,必须要指定一个挂载点,而这里并没有指明挂载点位于哪里。这就涉及下一个步骤,安装。
安装
文件系统的安装必须指定一个安装点。该安装点位于根文件系统的任一目录下。我的U盘安装在了/run/media下。把一个文件系统安装到一个安装点要用到的主要结构为mount

该结构体在/fs的Mount.h文件中被定义。
卸载
卸载文件系统就是将该文件系统的相关结构体从链表中释放。而在此之前,必须保证VFS中的超级块不为“脏”,而且没有该文件系统中的文件正在使用。卸载的内核实现是sys_umount。内核中源码位于fs/Namespace.c中,这里就不再详细介绍了。
不同文件系统间数据的传输
对于我上面演示的cp /run/media/pf/pf/0.png /home/pf命令,简单抽象的执行过程是这样的:
1.打开/run/media/pf/pf/0.png文件
2.在/home/pf文件下中新建0.png文件
3.读取/run/media/pf/pf/0.png文件数据到缓冲区
4.从缓冲区将数据写入/home/pf/0.png
5.关闭这两个文件
我们知道,我相互传数据的这两个文件系统是不同的,那么,不同的文件系统之间为什么可以用同一个系统调用来进行操作呢?
答案是linux的虚拟文件系统,那么内核中具体是如何实现的?
我这里以读取/run/media/pf/pf/0.png文件数据到缓冲区为例进行内核源码的分析。
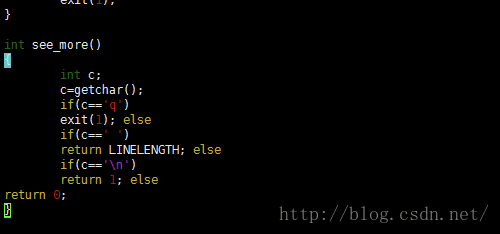
首先,当用了read()系统调用,会进入内核态调用sys_read()。这个函数的实现源码如下:
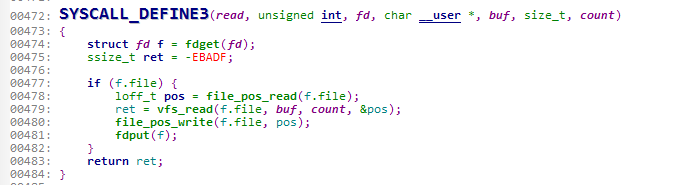
我们可以看到,这里使用了宏定义SYSCALL_DEFINE3,这样就可以传递变长参数。这里的重点执行函数在于vfs_read()。也就是说接下来会调用这个函数继续执行操作。我们进入其定义。
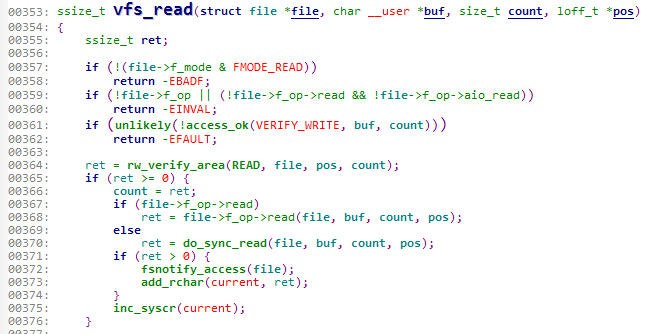
前面三条都是判断语句。重点在于后面的判断语句:如果file->f_op->read不存在则执行do_sync_read()函数,若存在,则执行file->f_op->read()函数。
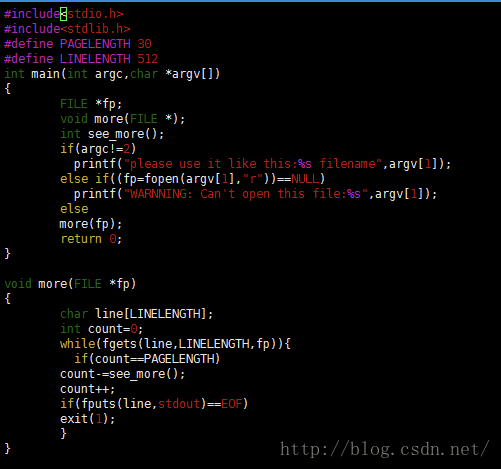
从这里可以很显然的看到,file与f_op都是结构体,file中定义了f_op,f_op中定义了read。现在,来看一下file结构体的样子。
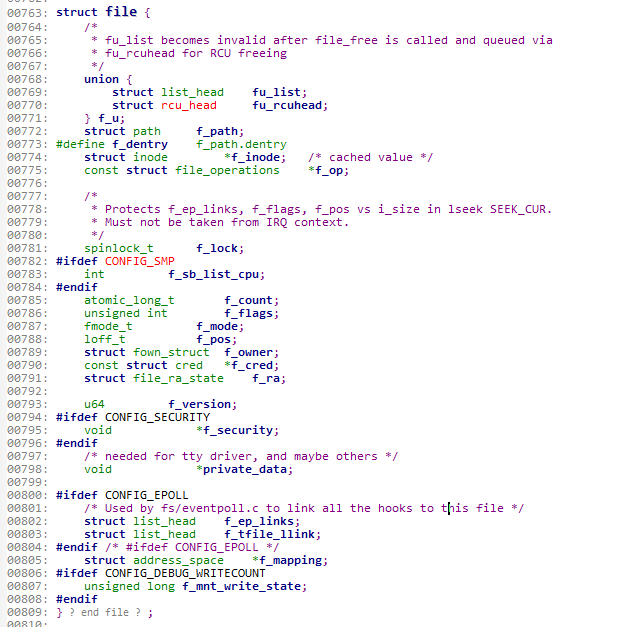
之前在基础章描述过它,这里不再重复描述。这里的重点是要找到f_op。
我们可以看到它是一个file_operations类型的结构体。
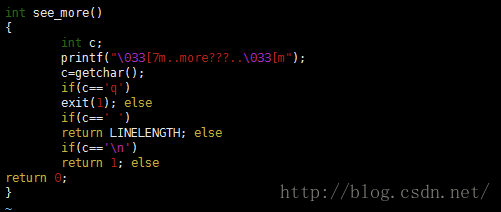
file_operations想必大家都知道,这是一个文件操作的结构体,其中定义的都是文件操作的函数,也就是接口。内核中源码实现如下:

这个结构体也位于/include/linux/Fs.h中。
想必现在大家就明白了,f_op调用的read()其实就是这个结构中定义的函数read。但是,这里的read并没有具体的实现。对于不同的文件系统,它们可能就有不同的实现方案。例如我linux的EXT4文件系统对于file_operations的实现与我U盘NTFS文件系统对于file_operations的实现就不相同。
EXT4文件系统file_operations结构的具体实现:
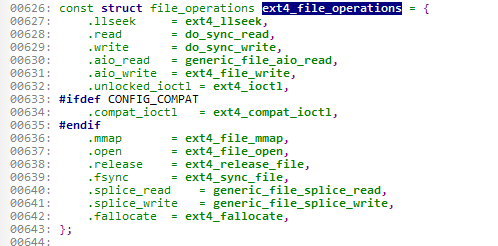
定义在/fs/ntfs/File.c中。
NTFS文件系统file_operations结构的具体实现:
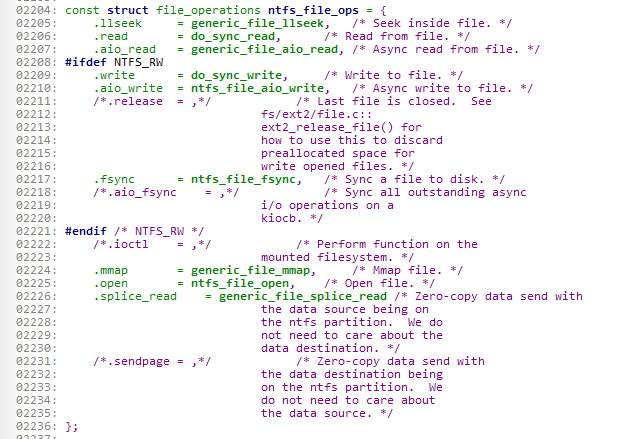
定义在/fs/ext4/File.c中。
可以看到,它们对于文件读、写等实现函数是相同的,但是对于有些函数如release、open等,实现函数则是不同的。
到此,大家可能就明白了linux文件系统是如何实现相同的系统调用实现对于不同文件系统的操作。实际上核心就是使用了file_operation这个接口实现的。
五、总结
实际上,在linux中有许多非常巧妙的设计,而且这些巧妙的设计也确实有其必然性。重要的是要学会透过现象看本质,抓住一般规律。本篇博客对于linux文件系统的分析还不算深入,今后还会进一步进行深入学习。