概述
本文试图用简单的语言描述Kubernetes主要组件的作用及其关系。这里我讲解的Kubernetes主要组件有API Server、Controller Manager、Scheduler、kubelet、kube-proxy,其中前三者运行于集群的Master节点,后两者运行于集群的Slave节点。接着描述了一下用于存储Kubernetes集群信息的Etcd,它是一个高可用、强一致性的服务发现存储仓库。最后,我抛出了一个我所遇到的一个问题。大家可以一同思考一下问题出在了哪里。
API Server
Kubernetes API Server通过kube-apiserver进程提供服务,该进程运行于Master节点上。
API Server是Kubernetes的核心组件,是各个组件通信的渠道,有如下特性:
1.集群管理的API入口
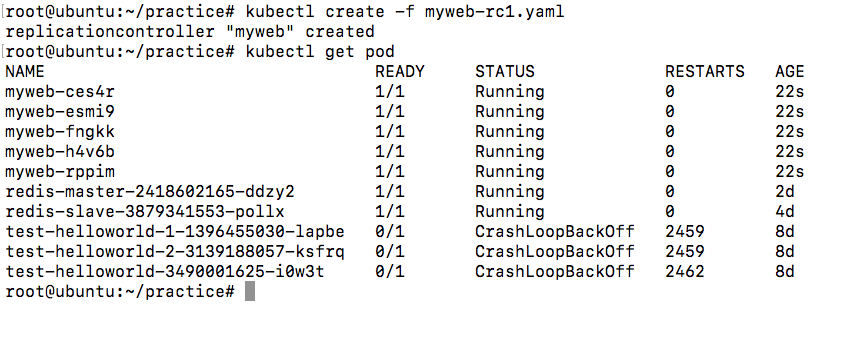
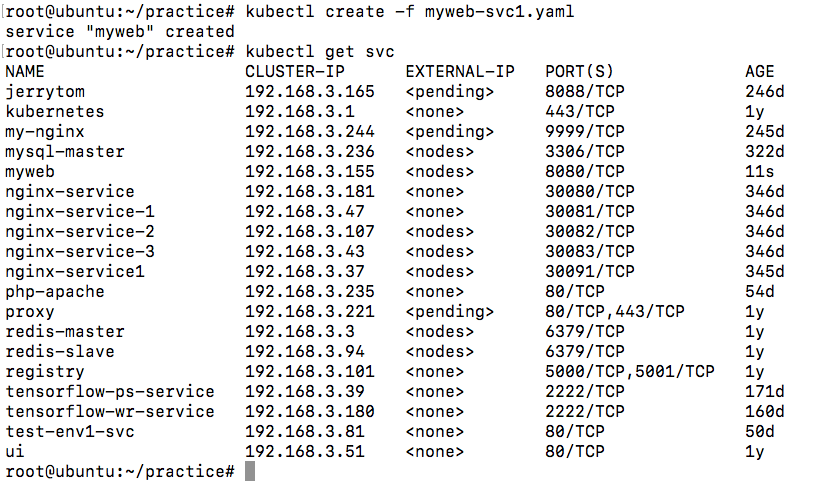
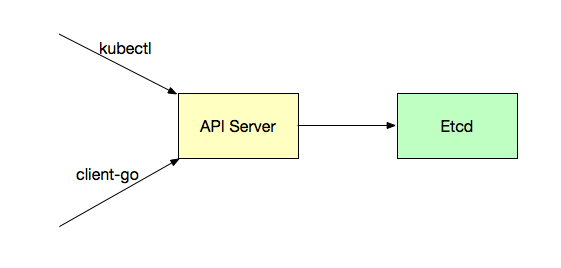
我们如果要创建一个资源对象如Deployment、Service、RC、ConfigMap等,都是要通过API Server的。
当然,我们可能是通过命令行的kubectl命令将一个yaml/json格式的文件create进行创建,还可能是通过写代码的方式使用如client-go这样的操作Kubernetes的第三方包来操作集群。总之,最终,都是通过API Server对集群进行操作的。通过API Server,我们就可以往Etcd中写入数据。Etcd中存储着集群的各种数据。
2.资源配额控制的入口
Kubernetes可以从各个层级对资源进行配额控制。如容器的CPU使用量、Pod的CPU使用量、namespace的资源数量等。这也是通过API Server进行配置的。将这些资源配额情况写入到Etcd中。
3.提供了完备的集群安全机制
Controller Manager
Replication Controller
副本控制器。用来保证Deployment或者RC中副本的数量的。
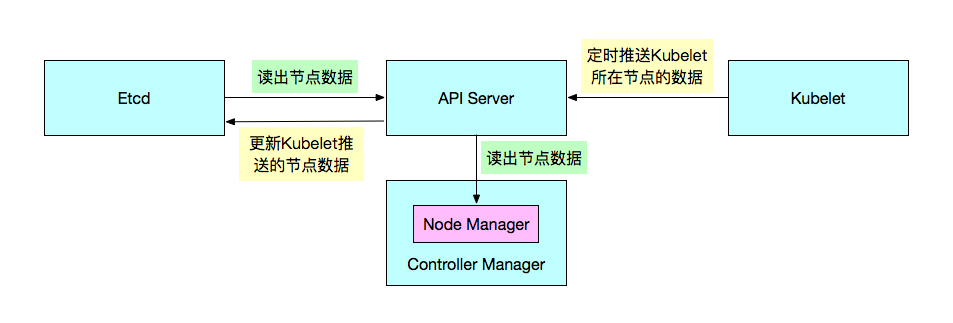
Node Controller
通过API Server监控Etcd中存储的关于节点的各类信息,这些信息是kubelet定时推给API Server的,由API Server写入到Etcd中。这些节点信息包括:节点健康状况、节点资源、节点名称、节点地址信息、操作系统版本、Docker版本、kubelet版本等。监控到节点信息若有异常情况,则会对节点进行某种操作,如节点状态变为故障状态,则删除节点与节点相关的Pod等资源的信息。
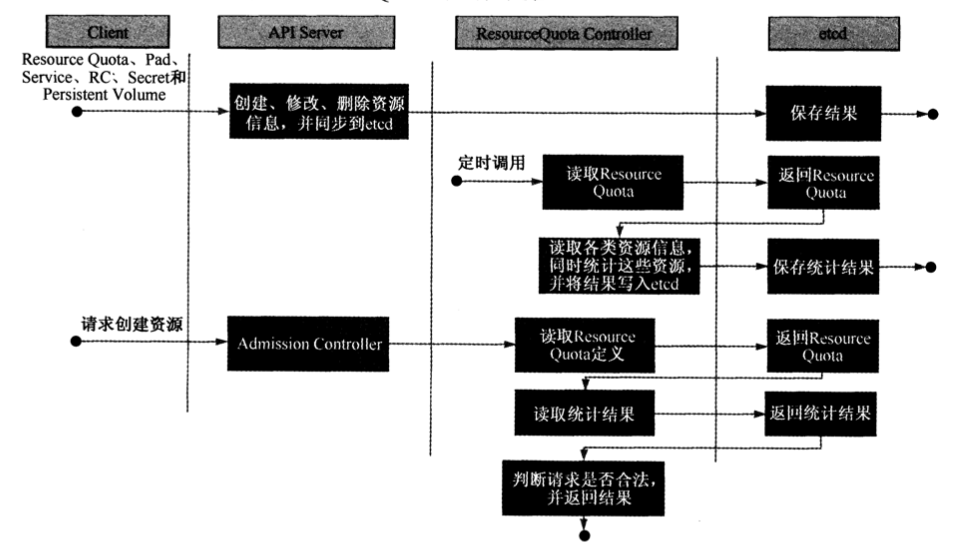
ResourceQuota Controller
将期望的资源配额信息通过API Server写入到Etcd中。然后ResourceQuota Controller会定时的统计这些信息,在系统请求资源的时候就会读取这些统计信息,如果不合法就不给分配该资源,则创建行为会报错。
Namespace Controller
用户是可以通过API Server创建新的namespace并保存在Etcd中的。Namespace Controller会定时通过API Server读取这些Namespace信息并做对应的对于Namespace的一些操作。
Endpoints Controller
负责生成和维护所有Endpoints对象的控制器。Endpoints表示了一个Service对应的所有Pod副本的访问地址。
一个Service可能对应了多个Endpoints,那么,在创建一个新的Service时Endpoints Controller就会生成对应的Endpoints。在Service被删除时,Endpoints Controller就会删除对应的Endpoints。等等。
Scheduler
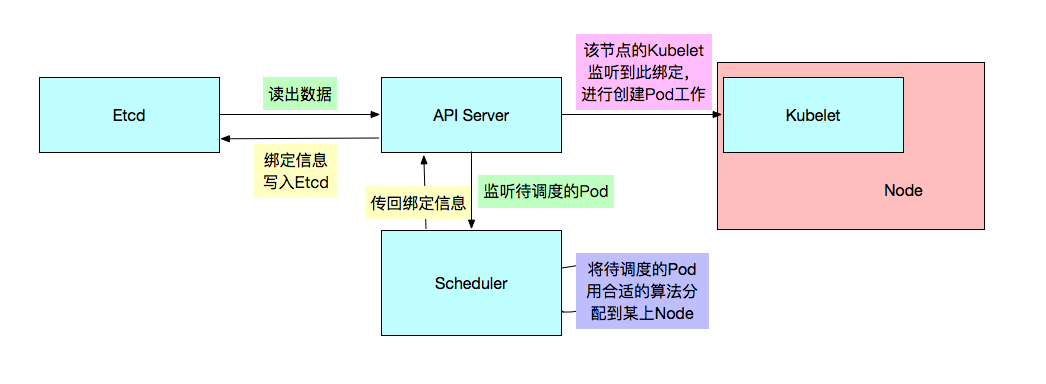
Kubernetes的调度器。Scheduler监听API Server,当需要创建新的Pod时。Scheduler负责选择该Pod与哪个Node进行绑定。将此绑定信息通过API Server写入到Etcd中。
若此时与Node A进行了绑定,那么A上的Kubelet就会从API Server上监听到此事件,那么该Kubelet就会做相应的创建工作。
此调度涉及到三个对象,待调度的Pod,可用的Node,调度算法。简单的说,就是使用某种调度算法为待调度的Pod找到合适的运行此Pod的Node。
关于Kubernetes Scheduler的调度算法,我会再另写一篇文章。
Kubelet
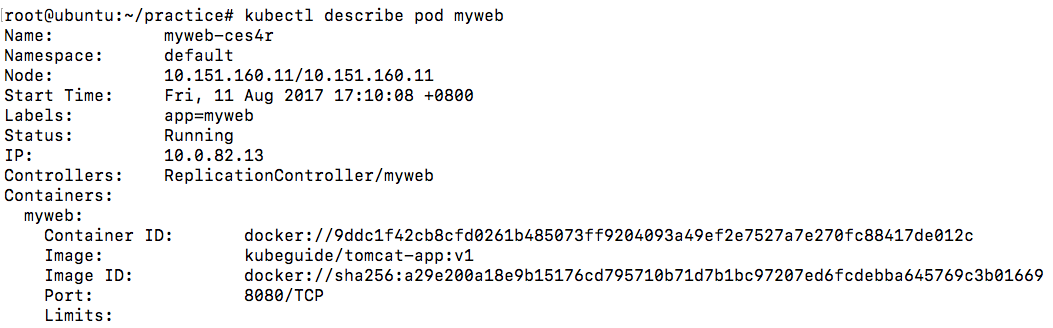
每个Node节点上都会有一个Kubelet负责Master下发到该节点的具体任务,管理该节点上的Pod和容器。而且会在创建之初向API Server注册自身的信息,定时汇报节点的信息。它还通过cAdvisor监控容器和节点资源。
节点管理
Kubelet在创建之初就会向API Server做自注册,然后会定时报告节点的信息给API Server写入到Etcd中。默认为10秒。
Pod管理
Kubelet会监听API Server,如果发现对Pod有什么操作,它就会作出相应的动作。例如发现有Pod与本Node进行了绑定。那么Kubelet就会创建相应的Pod且调用Docker Client下载image并运行container。
容器健康检查
有三种方式对容器做健康检查:
1.在容器内部运行一个命令,如果该命令的退出状态码为0,则表明容器健康。
2.TCP检查。
3.HTTP检查。
cAdvisor资源监控
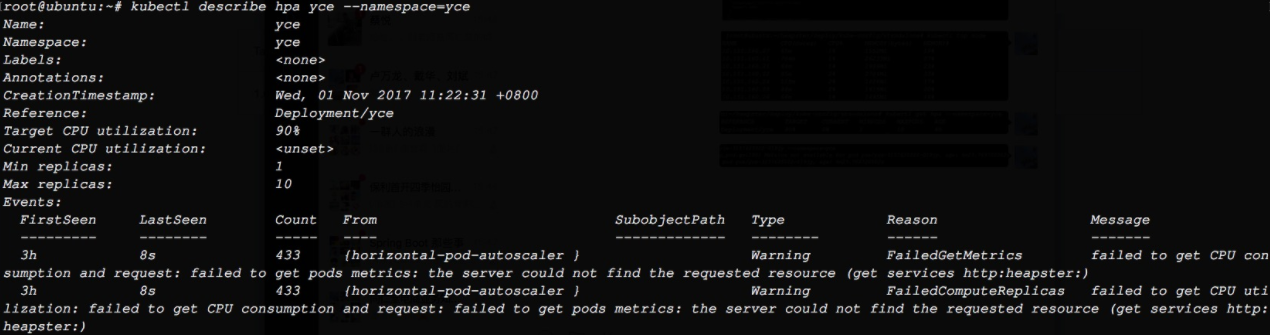
Kubelet通过cAdvisor对该节点的各类资源进行监控。如果集群需要这些监控到的资源信息,可以安装一个组件Heapster。
Heapster会进行集群级别的监控,它会通过Kubelet获取到所有节点的各种资源信息,然后通过带着关联标签的Pod分组这些信息。
如果再配合InfluxDB与Grafana,那么就成为一个完整的集群监控系统了。
Kube-proxy
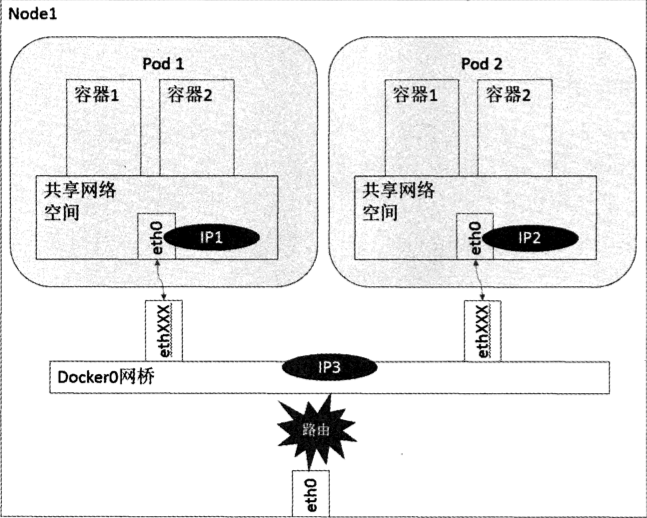
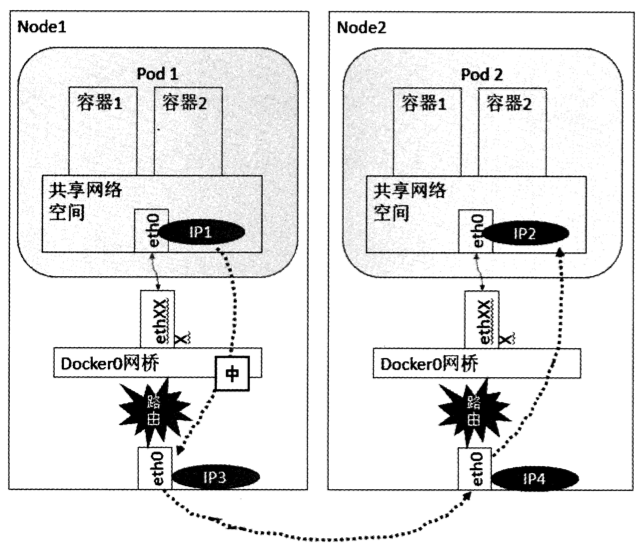
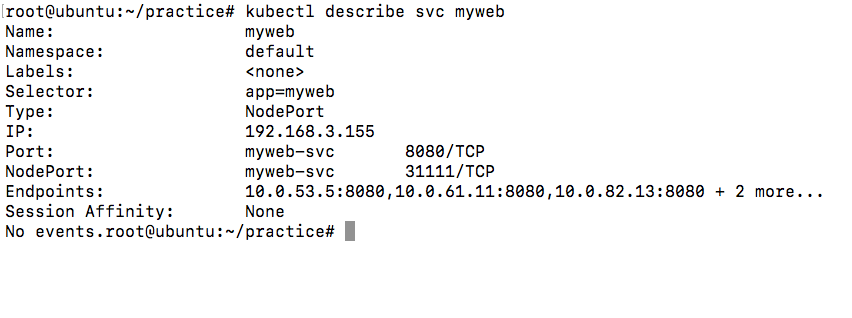
负责接收并转发请求。Kube-proxy的核心功能是将到Service的访问请求转发到后台的某个具体的Pod。
无论是通过ClusterIP+Port的方式还是NodeIP+NodePort的方式访问Service,最终都会被节点的Iptables规则重定向到Kube-proxy监听服务代理端口,该代理端口实际上就是SocketServer在本地随机打开的一个端口,SocketServer是Kube-proxy为每一个服务都会创建的“服务代理对象”的一部分。
当Kube-proxy监听到Service的访问请求后,它会找到最适合的Endpoints,然后将请求转发过去。具体的路由选择依据Round Robin算法及Service的Session会话保持这两个特性。
Etcd
Etcd一种k-v存储仓库,可用于服务发现程序。在Kubernetes中就是用Etcd来存储各种k-v对象的。
所以我也认为Etcd是Kubernetes的一个重要组件。当我们无论是创建Deployment也好,还是创建Service也好,各种资源对象信息都是写在Etcd中了。
各个组件是通过API Server进行交流的,然而数据的来源是Etcd。所以维持Etcd的高可用是至关重要的。如果Etcd坏了,任何程序也无法正常运行了。
以下是我的环境中的Etcd集群
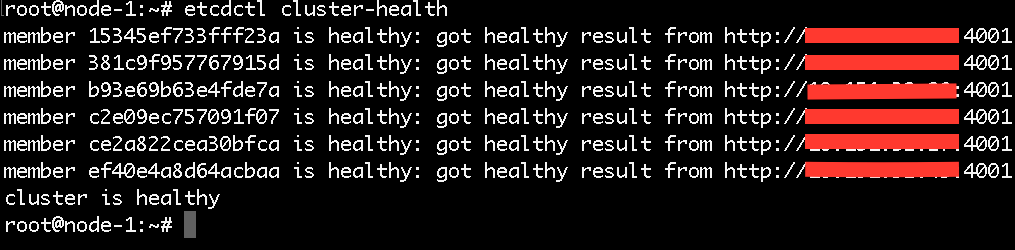
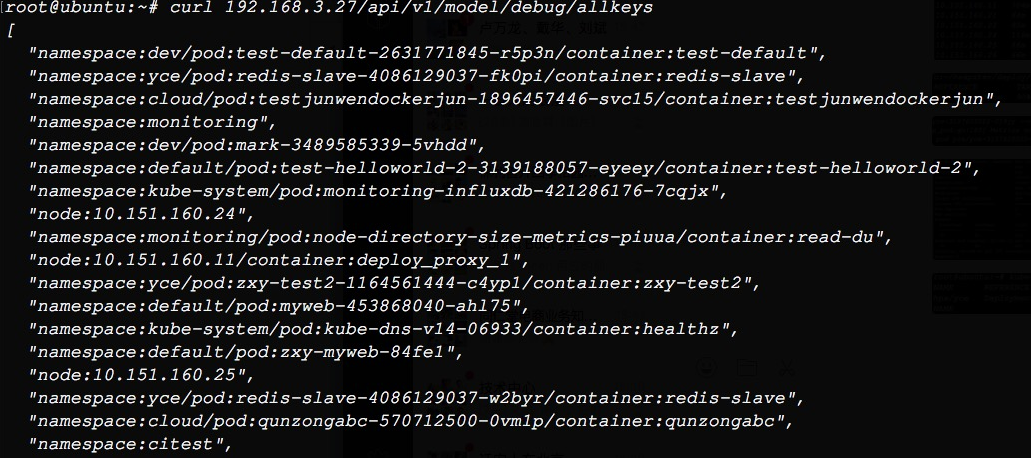
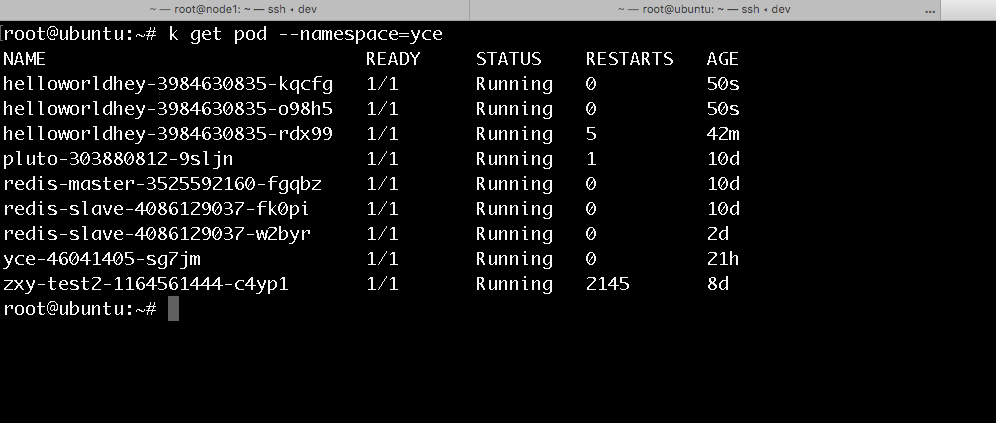
通过以下命令我们就可以看到该集群中yce这个namespace下的pod有哪些,此为目录,列出的都是键值
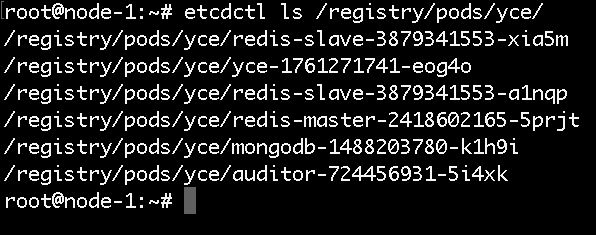
接下来,我们就可以查看某一个具体键值的value值
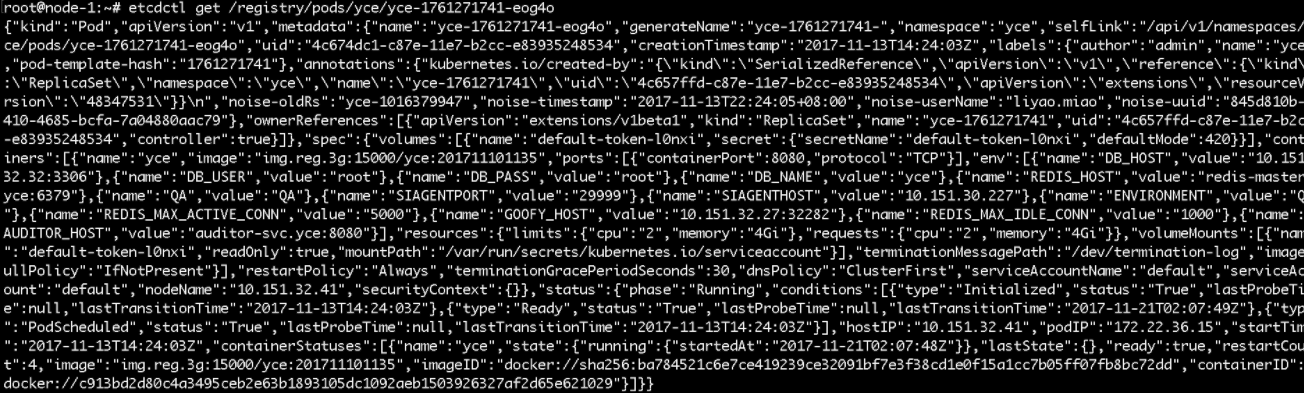
可以看到这个value值是一个Json格式的文件。
一个问题
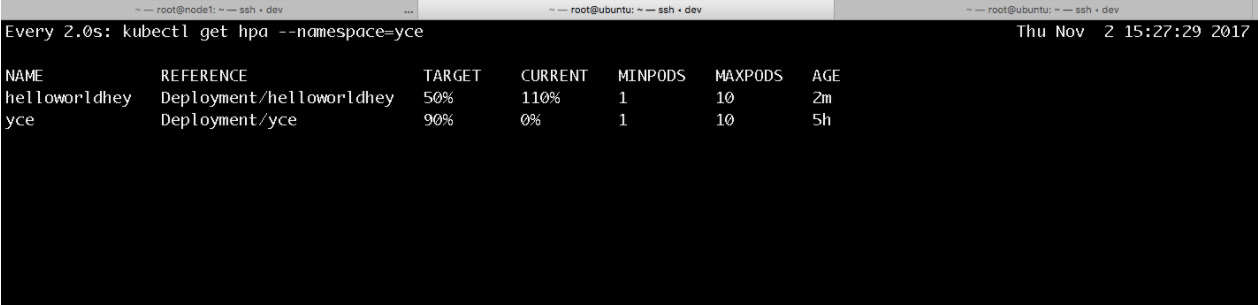
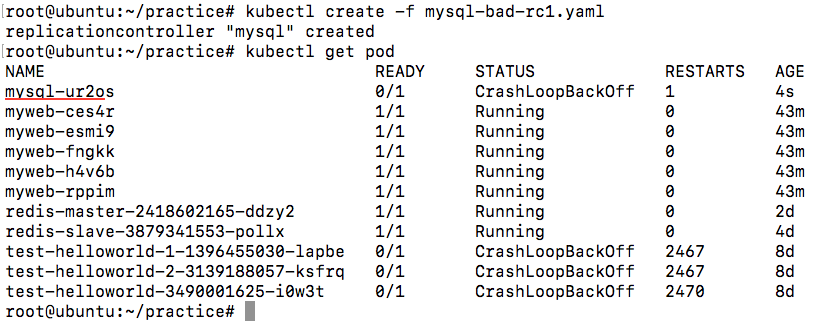
我做了一个实验,如果从Etcd中直接改yce这个deployment的Json值,从replicas的值从1改到3,发现deployment的desired值发生了变化,但是current值并没有变化,也就是说,Pod的数量并没有因为Etc中的值的改变而改变。难道是因为Replicas Controller没有监控到Etcd中的此变化?
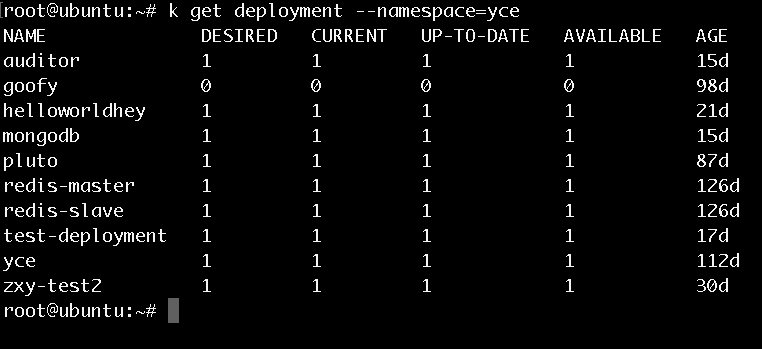
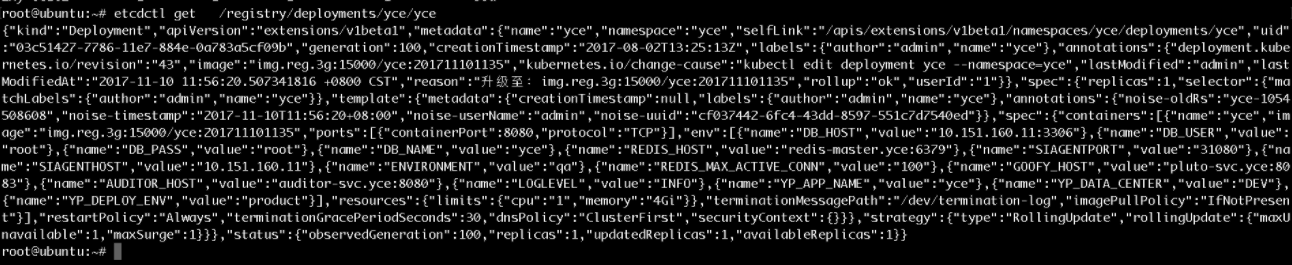

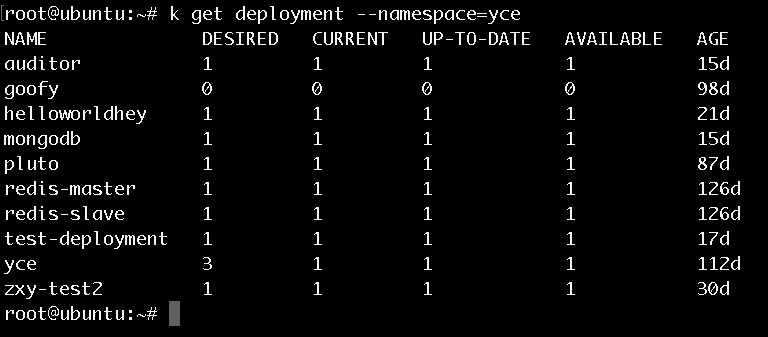
如上所示,更改了Etcd中deployment的replicas的值之后,可以用kubectl edit看到该deployment的replicas值确实发生了变化。但是deployment的current值却并无变化。
若是用kubectl edit更改deployment的replicas值就会发现deployment的current值是会发生变化的。请大家思考一下这是为什么。
总结
Kubernetes的这些组件各自分别有着重要的功能。它们之间协同工作,共同保证了Kubernetes对于容器化应用的自动管理。
其中API Server起着桥梁的作用,各个组件都要通过它进行交互。Controller Manager像是集群的大管家,管理着许多事务。Scheduler就像是一个调度亭,负责Pod的调度工作。
Kubelet则在每个节点上都有,像是一个执行者,真正创建、修改、销毁Pod的工作都是由它来具体执行。Kube-proxy像是负载均衡器,在外界需要对Pod进行访问时它作为代理进行路由工作,将具体的访问分给某一具体的Pod实例。
Etcd则是Kubernetes的数据中心,用来存储Kubernetes创建的各类资源对象信息。
这些组件缺一不可,无论少了哪一个Kubernetes都不能进行正常的工作。这里大概讲了下各组件的功能,感兴趣的可以分析Kubernetes的源码,github中就有。